Hi, I am trying to work on Segmentation with Unet on CamVid Dataset. Data has 32 classes, masks available are of [n,3,h,w]. I converted the masks in [n,32,h,w]. While during training using CrossEntropyloss Ii game target to criterion as target=target.argmax(1) which makes target of shape [n,1,h,w] while my model predictions are of shape [n,32,h,w]. But when test on test data result is not good.

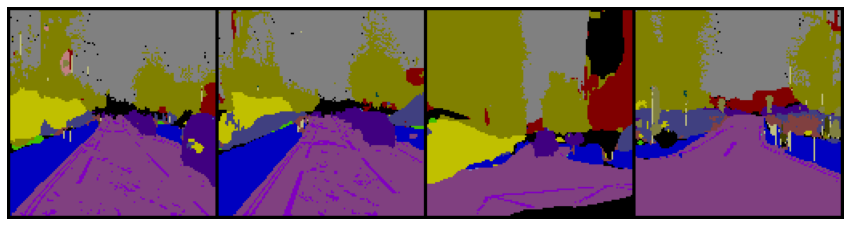
My code is Given:
def Double_Conv(input_channel, output_channel):
return nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
nn.Conv2d(output_channel, output_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True)
)
class UNet(nn.Module):
def __init__(self, no_of_cls):
super().__init__()
self.down1 = Double_Conv(3, 64)
self.down2 = Double_Conv(64, 128)
self.down3 = Double_Conv(128, 256)
self.down4 = Double_Conv(256, 512)
self.down5 = Double_Conv(512, 1024)
self.max_pool = nn.MaxPool2d(2)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.up4 = Double_Conv(512 + 1024, 512)
self.up3 = Double_Conv(256 + 512, 256)
self.up2 = Double_Conv(128 + 256, 128)
self.up1 = Double_Conv(64 + 128, 64)
self.lastConv = nn.Conv2d(64, no_of_cls, 1)
def forward(self, x):
conv1 = self.down1(x)
x = self.max_pool(conv1)
conv2 = self.down2(x)
x = self.max_pool(conv2)
conv3 = self.down3(x)
x = self.max_pool(conv3)
conv4 = self.down4(x)
x = self.max_pool(conv4)
x = self.down5(x)
x = self.upsample(x)
x = torch.cat([x, conv4], dim=1)
x = self.up4(x)
x = self.upsample(x)
x = torch.cat([x, conv3], dim=1)
x = self.up3(x)
x = self.upsample(x)
x = torch.cat([x, conv2], dim=1)
x = self.up2(x)
x = self.upsample(x)
x = torch.cat([x, conv1], dim=1)
x = self.up1(x)
out = self.lastConv(x)
return out
Training loop:
model.train()
stats = []
print('Training Started.....')
for epoch in range(epochs):
train_loss, valid_loss = 0,0
metrics = defaultdict(float)
for i, data in enumerate(trainloader):
inputs, mask, _ = data
inputs, mask = inputs.to(device), mask.to(device)
optimizer.zero_grad()
output = model(inputs.float())
target = mask.argmax(1)
loss = criterion(output, target.long())
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
train_loss = train_loss / len(trainloader.dataset)
with torch.no_grad():
model.eval()
for i, val_data in enumerate(validloader):
inp, masks, _ = val_data
inp, masks = inp.to(device), masks.to(device)
out = model(inp.float())
val_target = masks.argmax(1)
val_loss = criterion(out, val_target.long())
valid_loss += val_loss.item() * inp.size(0)
valid_loss = valid_loss / len(validloader.dataset)
model.optimizer = optimizer
stats.append([train_loss, valid_loss])
print('Epoch',epoch,':',f' Training Loss: {train_loss:.4f},', f' Validation Loss: {valid_loss:.4f}')
stat = pd.DataFrame(stats, columns=['train_loss', 'valid_loss'])