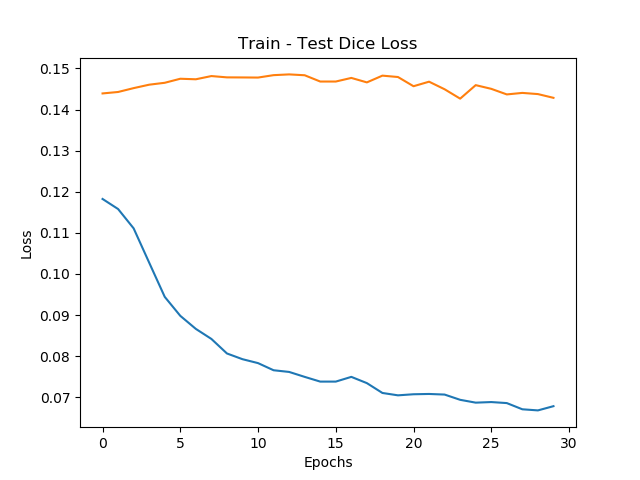
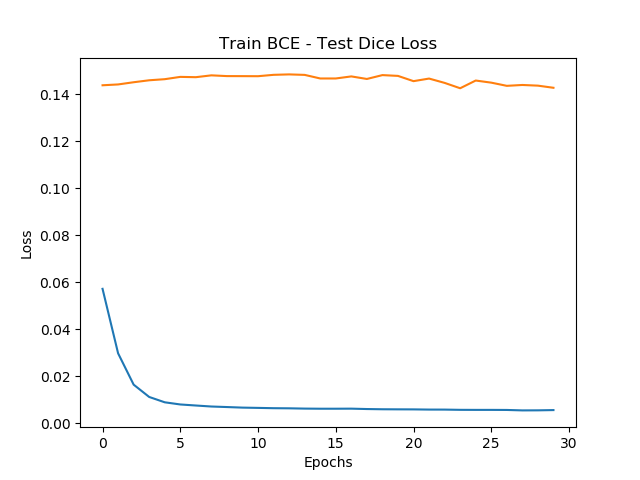
I’m using BCEWithLogitsLoss to optimise my model, and Dice Coefficient loss for evaluating train dice loss & test dice loss. However, although both my train BCE loss & train dice loss decrease after each epoch, my test dice loss doesn’t and plateaus early on. I have already tried batch norm and dropout, as well as experimented with both Adam and SGD using from 1 to 0.00001 as the learning rate. The only difference between experiments is that the value at which the loss plateaus is different, but all experiments plateau at approx the 1st epoch.
Notably, as my dataset size is extremely small (100 images in total), I opted for a 80-20 train-test split, and augmented the trainset (via random cropping, rotations, etc) to 640 images. Could my problem be related to the limited dataset size?
Here are my training graphs (first 30 epochs) for reference:
Since the train loss is consistently decreasing, it implies that your model has low bias. The plateued valid loss could indicate high variance. Furthermore, you have tried standard methods to avoid overfitting. Therefore, this seems to be the best you can do with the current model.
Below are three possible conclusions.
The train dataset size is small. No matter how well you learn on train data, you are unable to generalize to new distributions - > obtain more data.
The valid dataset could be of a vastly different distribution as compared to the train dataset - - > Try cross validation and verify whether it is indeed the size of the dataset rather than its distribution.
There is a possibility of a mixup in the testloader. Just before you give the input to the model, check and see whether you are giving in the image correctly. Make sure you apply the same scaling that was done during training. - - > fix if present.