Hello everyone,
I’m kinda new to deep learning and neural network.
I found some code on github which implements an UNet and tried to train it but for some reason it puts all the load on the CPU instead of the GPU.
I run on windows 10 and have NVIDIA GeForce RTX 2060 (which supports CUDA) with CUDA 10.1 installed (and it’s compatible CuDNN).
Python 3.8.2 and Pytorch 1.4.0.
When I excecute this line - “device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)”, it returns “device(type=‘cuda’)”. and I made sure to try this some methods to send the data (images and masks aswell) to the GPU:
- imgs = imgs.to(device=device, dtype=torch.float32)
- imgs = imgs.cuda()
- imgs = imgs.to(dtype=torch.float32).cuda()
and of course on the net itself: - net.to(device=device)
- net = net.cuda()
with no success (It still puts the load on the CPU instead of the GPU)
update:
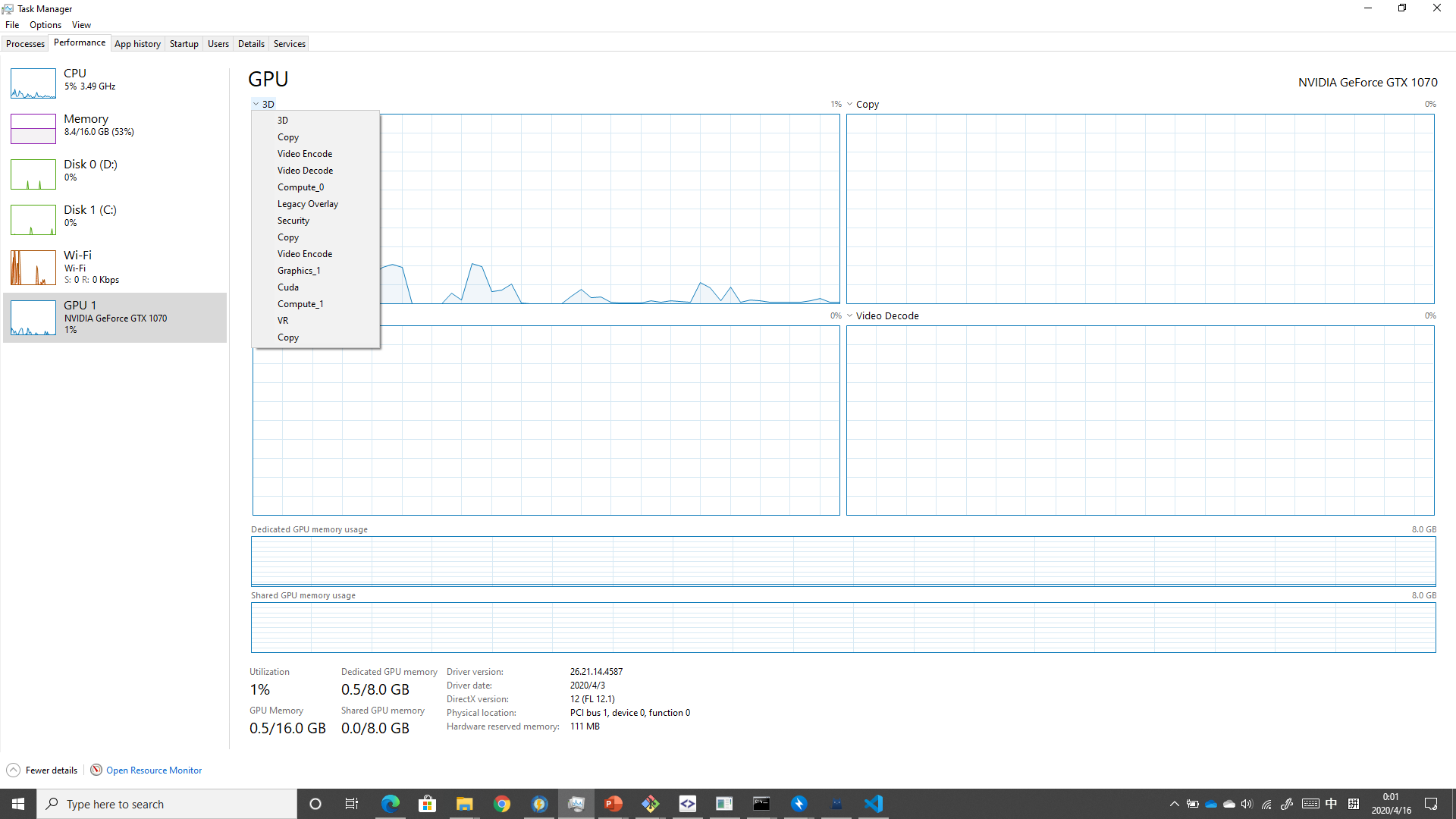
here you can see Task Manager windows during the training
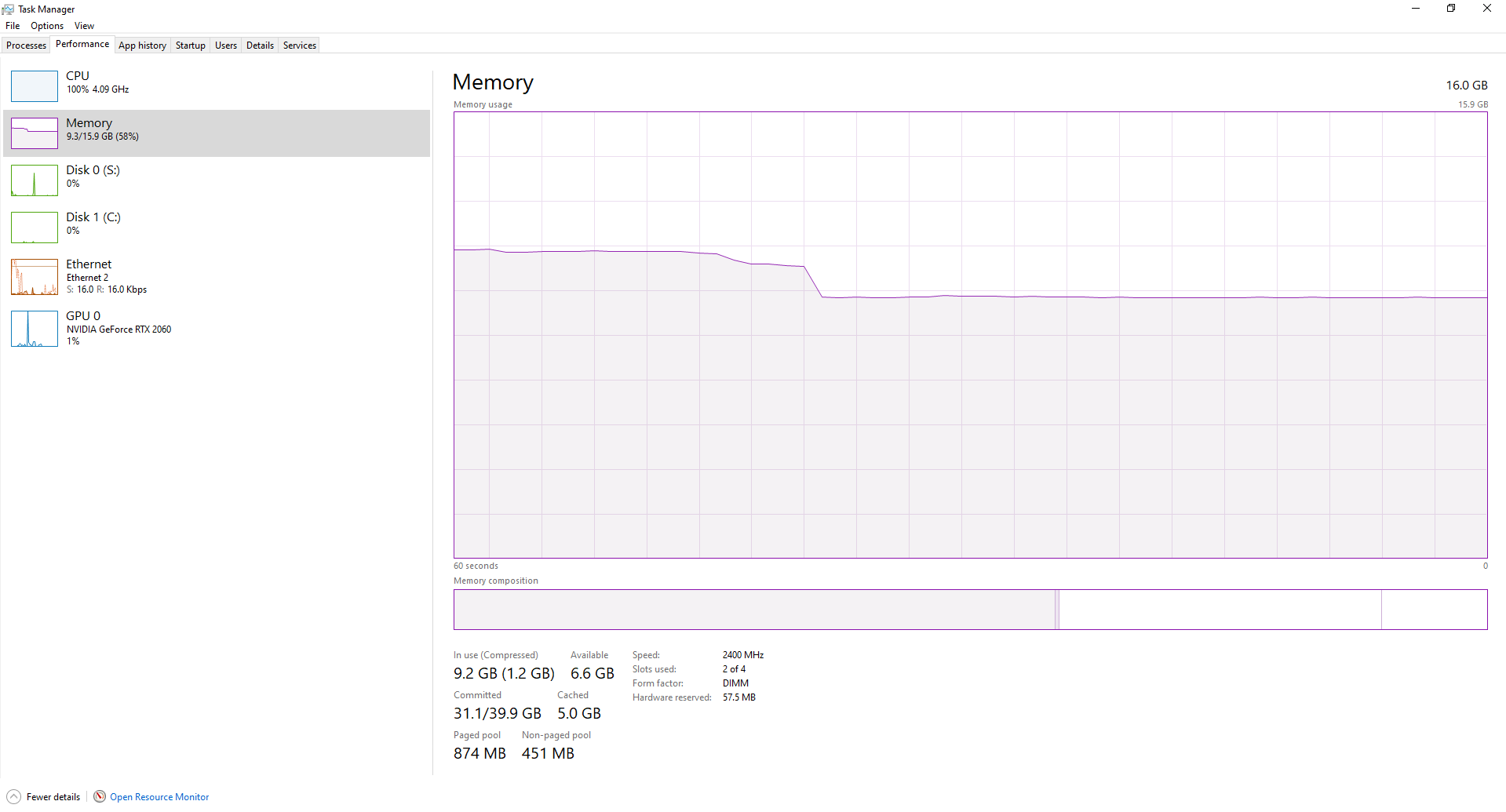
while if I run “nvidia-smi” in cmd I get something a bit different to my understanding
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 445.75 Driver Version: 445.75 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 2060 WDDM | 00000000:01:00.0 On | N/A |
| 86% 77C P2 157W / 170W | 5834MiB / 6144MiB | 95% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 2888 C+G ...me\Application\chrome.exe N/A |
| 0 N/A N/A 3204 C+G ...zf8qxf38zg5c\SkypeApp.exe N/A |
| 0 N/A N/A 4012 C+G ...es.TextInput.InputApp.exe N/A |
| 0 N/A N/A 5232 C+G ...app-0.4.2088\WhatsApp.exe N/A |
| 0 N/A N/A 5792 C+G ...w5n1h2txyewy\SearchUI.exe N/A |
| 0 N/A N/A 6160 C+G ...root\Office16\WINWORD.EXE N/A |
| 0 N/A N/A 6876 C+G ...b3d8bbwe\WinStore.App.exe N/A |
| 0 N/A N/A 7912 C+G ...perience\NVIDIA Share.exe N/A |
| 0 N/A N/A 10924 C+G ...in7x64\steamwebhelper.exe N/A |
| 0 N/A N/A 11824 C+G ...y\ShellExperienceHost.exe N/A |
| 0 N/A N/A 14056 C+G Insufficient Permissions N/A |
| 0 N/A N/A 14736 C Insufficient Permissions N/A |
| 0 N/A N/A 15956 C+G ...kyb3d8bbwe\Calculator.exe N/A |
| 0 N/A N/A 16364 C+G ...aming\Spotify\Spotify.exe N/A |
| 0 N/A N/A 16592 C+G ...32\CredentialUIBroker.exe N/A |
| 0 N/A N/A 16632 C+G C:\Windows\explorer.exe N/A |
| 0 N/A N/A 17728 C+G ...lPanel\SystemSettings.exe N/A |
| 0 N/A N/A 19072 C+G ...dows\System32\WWAHost.exe N/A |
| 0 N/A N/A 20132 C+G ...root\Office16\WINWORD.EXE N/A |
+-----------------------------------------------------------------------------+
First of all it seems like it using 95% of the GPU capacity (I ran this line before I started training an it was set on around 3%)
Secondly it says at the top right “CUDA Version 11.0” - what’s that all about?
I have no idea what i’m doing wrong…
Thanks in advance!
while if I run
here’s the full code (source):
import argparse
import logging
import os
import sys
import numpy as np
import torch
import torch.nn as nn
from torch import optim
from tqdm import tqdm
from eval import eval_net
from unet import UNet
from torch.utils.tensorboard import SummaryWriter
from utils.dataset import BasicDataset
from torch.utils.data import DataLoader, random_split
dir_img = 'data/imgs/'
dir_mask = 'data/masks/'
dir_checkpoint = 'checkpoints/'
def train_net(net,
device,
epochs=5,
batch_size=1,
lr=0.001,
val_percent=0.1,
save_cp=True,
img_scale=0.5):
dataset = BasicDataset(dir_img, dir_mask, img_scale)
n_val = int(len(dataset) * val_percent)
n_train = len(dataset) - n_val
train, val = random_split(dataset, [n_train, n_val])
train_loader = DataLoader(train, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True)
val_loader = DataLoader(val, batch_size=batch_size, shuffle=False, num_workers=8, pin_memory=True, drop_last=True)
writer = SummaryWriter(comment=f'LR_{lr}_BS_{batch_size}_SCALE_{img_scale}')
global_step = 0
logging.info(f'''Starting training:
Epochs: {epochs}
Batch size: {batch_size}
Learning rate: {lr}
Training size: {n_train}
Validation size: {n_val}
Checkpoints: {save_cp}
Device: {device.type}
Images scaling: {img_scale}
''')
optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min' if net.n_classes > 1 else 'max', patience=2)
if net.n_classes > 1:
criterion = nn.CrossEntropyLoss()
else:
criterion = nn.BCEWithLogitsLoss()
for epoch in range(epochs):
net.train()
epoch_loss = 0
with tqdm(total=n_train, desc=f'Epoch {epoch + 1}/{epochs}', unit='img') as pbar:
for batch in train_loader:
imgs = batch['image']
true_masks = batch['mask']
assert imgs.shape[1] == net.n_channels, \
f'Network has been defined with {net.n_channels} input channels, ' \
f'but loaded images have {imgs.shape[1]} channels. Please check that ' \
'the images are loaded correctly.'
imgs = imgs.to(device=device, dtype=torch.float32)
#imgs = imgs.float32().cuda()
#imgs = imgs.to(dtype=torch.float32).cuda()
#imgs = imgs.cuda()
mask_type = torch.float32 if net.n_classes == 1 else torch.long
true_masks = true_masks.to(device=device, dtype=mask_type)
#true_masks = true_masks.cuda
#true_masks = true_masks.to(dtype=mask_type).cuda()
#true_masks.cuda()
masks_pred = net(imgs)
loss = criterion(masks_pred, true_masks)
epoch_loss += loss.item()
writer.add_scalar('Loss/train', loss.item(), global_step)
pbar.set_postfix(**{'loss (batch)': loss.item()})
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_value_(net.parameters(), 0.1)
optimizer.step()
pbar.update(imgs.shape[0])
global_step += 1
if global_step % (len(dataset) // (10 * batch_size)) == 0:
for tag, value in net.named_parameters():
tag = tag.replace('.', '/')
writer.add_histogram('weights/' + tag, value.data.cpu().numpy(), global_step)
writer.add_histogram('grads/' + tag, value.grad.data.cpu().numpy(), global_step)
val_score = eval_net(net, val_loader, device)
scheduler.step(val_score)
writer.add_scalar('learning_rate', optimizer.param_groups[0]['lr'], global_step)
if net.n_classes > 1:
logging.info('Validation cross entropy: {}'.format(val_score))
writer.add_scalar('Loss/test', val_score, global_step)
else:
logging.info('Validation Dice Coeff: {}'.format(val_score))
writer.add_scalar('Dice/test', val_score, global_step)
writer.add_images('images', imgs, global_step)
if net.n_classes == 1:
writer.add_images('masks/true', true_masks, global_step)
writer.add_images('masks/pred', torch.sigmoid(masks_pred) > 0.5, global_step)
if save_cp:
try:
os.mkdir(dir_checkpoint)
logging.info('Created checkpoint directory')
except OSError:
pass
torch.save(net.state_dict(),
dir_checkpoint + f'CP_epoch{epoch + 1}.pth')
logging.info(f'Checkpoint {epoch + 1} saved !')
writer.close()
def get_args():
parser = argparse.ArgumentParser(description='Train the UNet on images and target masks',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('-e', '--epochs', metavar='E', type=int, default=5,
help='Number of epochs', dest='epochs')
parser.add_argument('-b', '--batch-size', metavar='B', type=int, nargs='?', default=1,
help='Batch size', dest='batchsize')
parser.add_argument('-l', '--learning-rate', metavar='LR', type=float, nargs='?', default=0.1,
help='Learning rate', dest='lr')
parser.add_argument('-f', '--load', dest='load', type=str, default=False,
help='Load model from a .pth file')
parser.add_argument('-s', '--scale', dest='scale', type=float, default=0.5,
help='Downscaling factor of the images')
parser.add_argument('-v', '--validation', dest='val', type=float, default=10.0,
help='Percent of the data that is used as validation (0-100)')
return parser.parse_args()
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
args = get_args()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f'Using device {device}')
# Change here to adapt to your data
# n_channels=3 for RGB images
# n_classes is the number of probabilities you want to get per pixel
# - For 1 class and background, use n_classes=1
# - For 2 classes, use n_classes=1
# - For N > 2 classes, use n_classes=N
net = UNet(n_channels=3, n_classes=1, bilinear=True)
logging.info(f'Network:\n'
f'\t{net.n_channels} input channels\n'
f'\t{net.n_classes} output channels (classes)\n'
f'\t{"Bilinear" if net.bilinear else "Transposed conv"} upscaling')
if args.load:
net.load_state_dict(
torch.load(args.load, map_location=device)
)
logging.info(f'Model loaded from {args.load}')
net.to(device=device)
#net = net.cuda()
#net.cuda()
# faster convolutions, but more memory
# cudnn.benchmark = True
try:
train_net(net=net,
epochs=args.epochs,
batch_size=args.batchsize,
lr=args.lr,
device=device,
img_scale=args.scale,
val_percent=args.val / 100)
except KeyboardInterrupt:
torch.save(net.state_dict(), 'INTERRUPTED.pth')
logging.info('Saved interrupt')
try:
sys.exit(0)
except SystemExit:
os._exit(0)