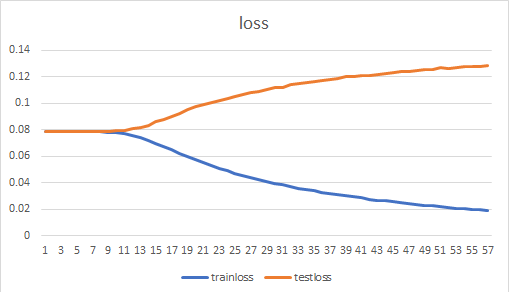I use Unet for image regression (phase reconstruction). Input is 224 by 224 grey image, out put is also 224 by 224 image.
Choose 100,000 images as the training set and 1000 images as the test set. Loss function selection
MSE (), the optimizer selects Adam. When the learning rate is 0.01, the loss has not changed. Changed to lr = 0.00001, the loss of the training set began to decline, but the loss of the test set continued to rise. It feels like the network is overfitting before it learns the rules.
The net is as following:
class DoubleConv(nn.Module):
def __init__(self, in_ch, out_ch):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, input):
return self.conv(input)
class Unet(nn.Module):
def __init__(self,in_ch,out_ch):
super(Unet, self).__init__()
self.conv1 = DoubleConv(in_ch, 64)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = DoubleConv(64, 128)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = DoubleConv(128, 256)
self.pool3 = nn.MaxPool2d(2)
self.conv4 = DoubleConv(256, 512)
self.pool4 = nn.MaxPool2d(2)
self.conv5 = DoubleConv(512, 1024)
self.up6 = nn.ConvTranspose2d(1024, 512, 2, stride=2)
self.conv6 = DoubleConv(1024, 512)
self.up7 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.conv7 = DoubleConv(512, 256)
self.up8 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.conv8 = DoubleConv(256, 128)
self.up9 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.conv9 = DoubleConv(128, 64)
self.conv10 = nn.Conv2d(64,out_ch, 1)
def forward(self,x):
c1=self.conv1(x)
p1=self.pool1(c1)
c2=self.conv2(p1)
p2=self.pool2(c2)
c3=self.conv3(p2)
p3=self.pool3(c3)
c4=self.conv4(p3)
p4=self.pool4(c4)
c5=self.conv5(p4)
up_6= self.up6(c5)
merge6 = torch.cat([up_6, c4], dim=1)
c6=self.conv6(merge6)
up_7=self.up7(c6)
merge7 = torch.cat([up_7, c3], dim=1)
c7=self.conv7(merge7)
up_8=self.up8(c7)
merge8 = torch.cat([up_8, c2], dim=1)
c8=self.conv8(merge8)
up_9=self.up9(c8)
merge9=torch.cat([up_9,c1],dim=1)
c9=self.conv9(merge9)
c10=self.conv10(c9)
out = nn.Sigmoid()(c10)
return out
Train model:
#训练模型
def train():
model = Unet(1, 1).to(device)
# model.load_state_dict(torch.load(args.ckpt)) #加载之前学习过的模型参数
batch_size = args.batch_size
#criterion = nn.BCEWithLogitsLoss()
#criterion = nn.CrossEntropyLoss() #多通道输出,表示四个类别
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(),lr=0.00001)
#训练集数据
liver_dataset_train = LiverDataset("data/train",transform=x_transforms,target_transform=y_transforms)
dataloaders_train= DataLoader(liver_dataset_train, batch_size=batch_size, shuffle=True, num_workers=4)
#验证集数据
liver_dataset_val = LiverDataset("data/test",transform=x_transforms,target_transform=y_transforms)
dataloaders_val = DataLoader(liver_dataset_val, batch_size=1)
train_model(model, criterion, optimizer, dataloaders_train,dataloaders_val)
import torch
import argparse
from torch.utils.data import DataLoader
from torch import nn, optim
from torchvision.transforms import transforms
from unet import Unet
from dataset import LiverDataset
torch.backends.cudnn.benchmark = True
import time
import numpy as np
# 是否使用cuda
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) ])
#数据归一化 ToTensor()能够把灰度范围从0-255变换到0-1之间,
#而后面的transform.Normalize()则把0-1变换到(-1,1).
y_transforms = transforms.ToTensor() # mask只需要转换为tensor tensor的范围是0-1,
def train_model(model, criterion, optimizer, dataload_train,dataload_val, num_epochs=100):
since = time.time()
#动态设置学习参数
lr_list =[]
for epoch in range(num_epochs):
if epoch % 5 ==0:
for p in optimizer.param_groups:
p["lr"] *=1
lr_list.append(optimizer.state_dict()["param_groups"][0]["lr"])
model.train()
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('lr{}'.format(optimizer.param_groups[0]['lr']))
print('-' * 10)
dt_size = len(dataload_train.dataset)
epoch_loss = 0
step = 0
for x, y in dataload_train:
step += 1
inputs = x.to(device) #所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
labels = y.to(device) #
#交叉熵损失函数定义中,如果是做语义分割任务是得到一张【h,w】的语义图,那么input=【n,c,h,w】,target=【n,h,w】。
# zero the parameter gradients
optimizer.zero_grad()
# forward
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print("%d/%d,train_loss:%0.5f" % (step, (dt_size - 1) // dataload_train.batch_size + 1, loss.item()))
print("epoch %d train_loss:%0.5f" % (epoch, epoch_loss/step))
##保存每一轮的loss数据
#f = open("Train_loss.txt","a")
#f.write("epoch %d train_loss:%0.3f\n" %(epoch,epoch_loss/step))
torch.save(model.state_dict(),'./weights/weights_%d.pth' % epoch) #保存每一轮的模型的权重数据
#torch.save(model.state_dict(), 'weights_%d.pth' % epoch) #保存最后模型数据
#求验证集loss并保存
model.eval()
with torch.no_grad():
eval_loss = 0
step2=0
for x, y_true in dataload_val:
step2 += 1
x = x.to(device)
y_true = y_true.to(device)
y_out = model(x)
loss = criterion(y_out,y_true)
eval_loss+=loss.item()
print("epoch %d test_loss:%0.5f" % (epoch, eval_loss/step2))
#保存每一轮的loss数据
f = open("train_loss.txt","a")
f.write("epoch %d trian_loss:%0.5f test_loss: %0.5f\n" %(epoch,epoch_loss/step,eval_loss/step2))
#显示并保存训练过程耗费时间
time_elapsed=time.time()-since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed//60, time_elapsed%60))
f = open("time.txt","a")
f.write("Training complete in {:.0f}m {:.0f}s".format(time_elapsed//60, time_elapsed%60)) #记录并保存训练时间
return model
The loss is as following: