Hi,
As the title says, I am training a custom UNet model on a simple dataset (Oxford IIT Pet). I am not using the torchvision.data dataset, but rather a dataset that I downloaded from here.
No matter what I do, my validation loss doesn’t converge. It starts decreasing then it after a few epochs it starts increasing until the end of the training. Here’s how the loss progress looks like:
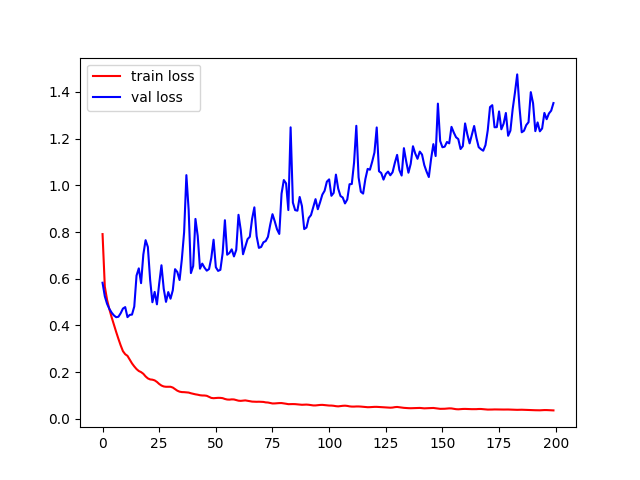
Here’s how I am creating the dataset and the transforms:
class SemanticSegDataset(Dataset):
def __init__(self, path_to_data, img_transforms, labels_transforms) -> None:
super().__init__()
self.img_transforms = img_transforms
self.labels_transforms = labels_transforms
path_to_images = os.path.join(path_to_data, "images")
path_to_annots = os.path.join(path_to_data, "annotations")
self.images_paths = sorted(glob(path_to_images + "/*.jpg"))
self.annots_paths = sorted(glob(path_to_annots + "/*.png"))
print(f'len(self.images_paths) = {len(self.images_paths)}')
assert(len(self.images_paths)==len(self.annots_paths))
def check_data_validity(self):
print("Checking data validity...")
for img, annot in zip(self.images_paths, self.annots_paths):
img = os.path.basename(img)[:-4]
annot = os.path.basename(annot)[:-4]
assert(img==annot)
print("Data seems good.")
def __len__(self):
return len(self.images_paths)
def __getitem__(self, index):
if index >= 0 and index < len(self.images_paths):
image = Image.open(self.images_paths[index]).convert('RGB')
annot = Image.open(self.annots_paths[index]) #.convert('L')
# seed = random.randint(0, 1000)
seed = torch.initial_seed()
random.seed(seed)
torch.manual_seed(seed)
img_tensor = self.img_transforms(image).float()
annot_tensor = self.labels_transforms(annot)
# state = torch.get_rng_state()
# img_tensor = self.aug_transforms(img_tensor)
# torch.set_rng_state(state)
# annot_tensor = self.aug_transforms(annot_tensor)
# out_annot_tensor = torch.zeros((1, annot_tensor.shape[1], annot_tensor.shape[2]), dtype=torch.long)
# tolerance = 1e-4
# mask_background = torch.isclose(annot_tensor, torch.tensor([0.0078]), atol=tolerance)
# mask_object = torch.isclose(annot_tensor, torch.tensor([0.0039]), atol=tolerance)
# mask_edge = torch.isclose(annot_tensor, torch.tensor([0.0118]), atol=tolerance)
# # background
# out_annot_tensor[mask_background] = 0
# # object
# out_annot_tensor[mask_object] = 1
# # edge
# out_annot_tensor[mask_edge] = 2
return img_tensor, annot_tensor
else:
print(f"Index {index} out of range! Falling back to index 0.")
return self.__getitem__(0)
def tensor_trimap(t):
x = t * 255
x = x.to(torch.long)
x = x - 1
return x
train_img_tranforms = T.Compose([
T.Resize((572, 572), interpolation=T.InterpolationMode.NEAREST_EXACT),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
# T.RandomHorizontalFlip(),
# T.RandomVerticalFlip(),
# T.GaussianBlur(kernel_size=3),
])
train_labels_transforms = T.Compose([
T.Resize((572, 572), interpolation=T.InterpolationMode.NEAREST),
T.ToTensor(),
# T.PILToTensor(),
# T.ConvertImageDtype(torch.long),
T.Lambda(tensor_trimap)
])
val_img_transforms = T.Compose([
T.Resize((572, 572), interpolation=T.InterpolationMode.NEAREST_EXACT),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
val_labels_transforms = T.Compose([
T.Resize((572, 572), interpolation=T.InterpolationMode.NEAREST),
T.ToTensor(),
# T.PILToTensor(),
# T.ConvertImageDtype(torch.long),
T.Lambda(tensor_trimap)
])
Here’s my UNet model architecture:
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class OtherUNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(OtherUNet, self).__init__()
self.model_name = "pytorch_unet"
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = (DoubleConv(n_channels, 64))
self.down1 = (Down(64, 128))
self.down2 = (Down(128, 256))
self.down3 = (Down(256, 512))
factor = 2 if bilinear else 1
self.down4 = (Down(512, 1024 // factor))
self.up1 = (Up(1024, 512 // factor, bilinear))
self.up2 = (Up(512, 256 // factor, bilinear))
self.up3 = (Up(256, 128 // factor, bilinear))
self.up4 = (Up(128, 64, bilinear))
self.outc = (OutConv(64, n_classes))
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
def use_checkpointing(self):
self.inc = torch.utils.checkpoint(self.inc)
self.down1 = torch.utils.checkpoint(self.down1)
self.down2 = torch.utils.checkpoint(self.down2)
self.down3 = torch.utils.checkpoint(self.down3)
self.down4 = torch.utils.checkpoint(self.down4)
self.up1 = torch.utils.checkpoint(self.up1)
self.up2 = torch.utils.checkpoint(self.up2)
self.up3 = torch.utils.checkpoint(self.up3)
self.up4 = torch.utils.checkpoint(self.up4)
self.outc = torch.utils.checkpoint(self.outc)
def save_model(self):
os.makedirs("models", exist_ok=True)
torch.save(self.state_dict(), f"models/{self.model_name}.pt")
Here’s my loss function:
def calc_loss(pred, target, metrics, ce_weight=0.5):
# print(f"pred.shape = ", pred.shape)
# print("target.shape = ", target.shape)
# print("torch.unique(target) = ", torch.unique(target))
ce = F.cross_entropy(pred, target)
# pred = F.sigmoid(pred)
# dice = dice_loss(pred, target)
# loss = ce * ce_weight + dice * (1 - ce_weight)
metrics['ce'] += ce.data.cpu().numpy() * target.size(0)
# metrics['dice'] += dice.data.cpu().numpy() * target.size(0)
# metrics['loss'] += loss.data.cpu().numpy() * target.size(0)
return ce #loss
Here’s my training loop:
tr_batch_size = 16
val_batch_size = 8
tr_dataloader = DataLoader(train_dataset, batch_size=tr_batch_size, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=val_batch_size)
model = OtherUNet(n_channels=3, n_classes=3)
model.to(device=device)
optimizer = torch.optim.RMSprop(model.parameters(),
lr=1e-4, weight_decay=1e-6, momentum=0.999, foreach=True)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.00001, max_lr=0.001, cycle_momentum=False) # goal: maximize Dice score
tr_loss_values = []
val_loss_values = []
current_best_val_loss = 10.0
metrics = defaultdict(float)
for epoch in range(epochs):
print("Epoch: ", epoch)
model.train()
running_tr_loss = 0.0
# Train
for i, (images, labels) in enumerate(tqdm(train_dataloader)):
optimizer.zero_grad()
images, labels = images.to(device), labels.to(device)
labels = labels.squeeze(1)
outputs = model(images)
# print("outputs.shape = ", outputs.shape)
loss = calc_loss(outputs, labels, metrics)
loss.backward()
optimizer.step()
running_tr_loss += loss.item()
# print("running loss: ", running_loss)
avg_tr_loss = running_tr_loss / len(train_dataloader)
print(f"train loss: {avg_tr_loss}")
tr_loss_values.append(avg_tr_loss)
# Validate
model.eval()
running_val_loss = 0.0
dice_score = 0.0
for i, (images, labels) in enumerate(tqdm(val_dataloader)):
images, labels = images.to(device), labels.to(device)
labels = labels.squeeze(1)
outputs = model(images)
loss = calc_loss(outputs, labels, metrics)
running_val_loss += loss.item()
avg_val_loss = running_val_loss / len(val_dataloader)
scheduler.step(avg_val_loss)
print(f"validation loss: {avg_val_loss}")
val_loss_values.append(avg_val_loss)
if avg_val_loss <= current_best_val_loss:
# Saving model
model.save_model()
current_best_val_loss = avg_val_loss
print(f"Validation loss went down. Saving newer model at epoch: {epoch}")
# Saving loss progress
plt.figure()
plt.plot(np.arange(0, epoch+1, 1), tr_loss_values, color="r", label="train loss")
plt.plot(np.arange(0, epoch+1, 1), val_loss_values, color='b', label="val loss")
plt.legend()
plt.savefig("unet_loss.png")
plt.close()
I copied the important parts of my code and not all of it just to keep the post clear.
Any ideas about why the validation loss is not converging? Is it just overfitting?
Btw, I have tried 2 other variations of UNet to see if it’s an issue with the architecture. But the issue persists.