I’m working on a classification problem (500 classes). My NN has 3 fully connected layers, followed by an LSTM layer. I use nn.CrossEntropyLoss() as my loss function. To tackle the problem of class imbalance, I use sklearn’s class_weight while initializing the loss
from sklearn.utils import class_weight
class_weights = class_weight.compute_class_weight(class_weight='balanced', classes=np.unique(y_org), y=y_org)
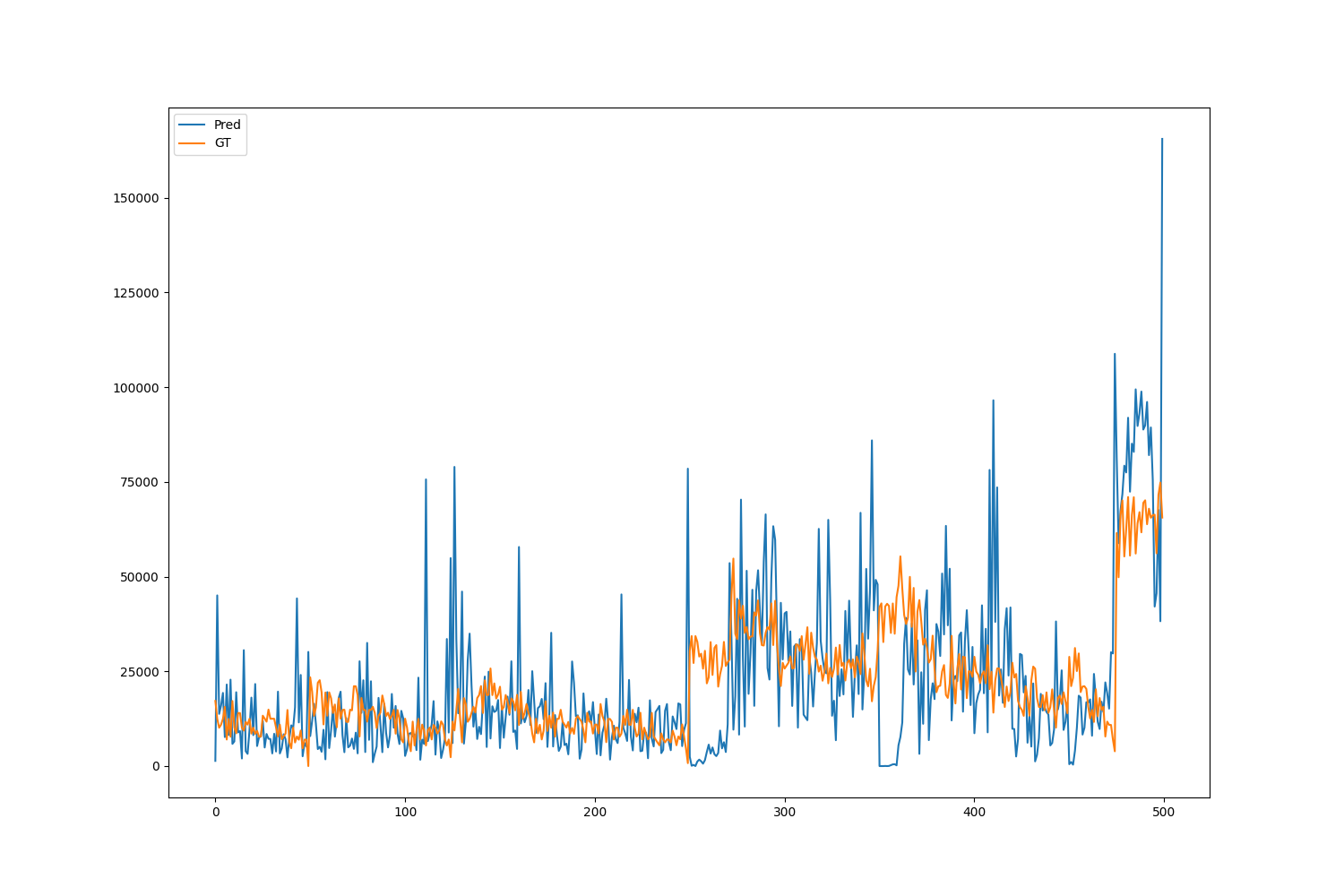
The below plots show the number of predictions made per class
Here, x-axis represents the class and y-axis is the number of times it occurred (as prediction and as ground truth).
The pattern observed here is that the ground truth and predicted class almost always complement each other. i.e., a class is predicted more times when it’s available less number of times in the ground truth and vice versa (every peak of the blue curve has a dip in orange curve and vice versa). What could be going wrong here?
In principle, nothing looks wrong here. When using weighted cross-entropy, the loss is adjusted based on the frequency with a weight between 0 and 1. Now normally this works just fine, but since you have 500 classes I suspect your minority classes are boosted a lot.
You can actually test it pretty easily.
from sklearn.utils import class_weight
test = []
for i in range(500):
if i<10:
test = test + [i] * 50
else:
test = test + [i] * 1000
class_weights=class_weight.compute_class_weight(class_weight='balanced',classes=np.unique(test), y=test)
print(class_weights[0], class_weights[-1])
And you’ll get 19.62 , 0.981. So 10 minority classes have a loss weight of 20, which is enough of a reason for the model to learn to over-predict them. Keep in mind though that in principle there’s nothing wrong with weighting the loss, in the long run, the other classes should be learned as well. If the model really struggles you could try using the focal loss, based on cross-entropy but with a different weighting approach.