Hello everyone,
I am training a transformer with a custom FeedForward layer and it’s causing unexpected efficiency issues. This layer entails two heavy batched matrix multiplications, implemented with torch.bmm
My code is basically:
def my_layer(x):
x = torch.bmm(x,tensor_1) #call it operation1
x = torch.relu_(x)
x = torch.bmm(x,tensor_2) #call it operation2
In my case, the shape of x is always torch.Size([1024, 256, 512]), and shape of tensor_1 and tensor_2 is torch.Size([1024, 512, 512]).
As seen above, both operation1 and operation2 implement the exact same type of operation with tensors that are identical in shape and type (the shape of x stays the same throughout this code), and yet the first one takes significantly more time than the other. The timings look as follows:
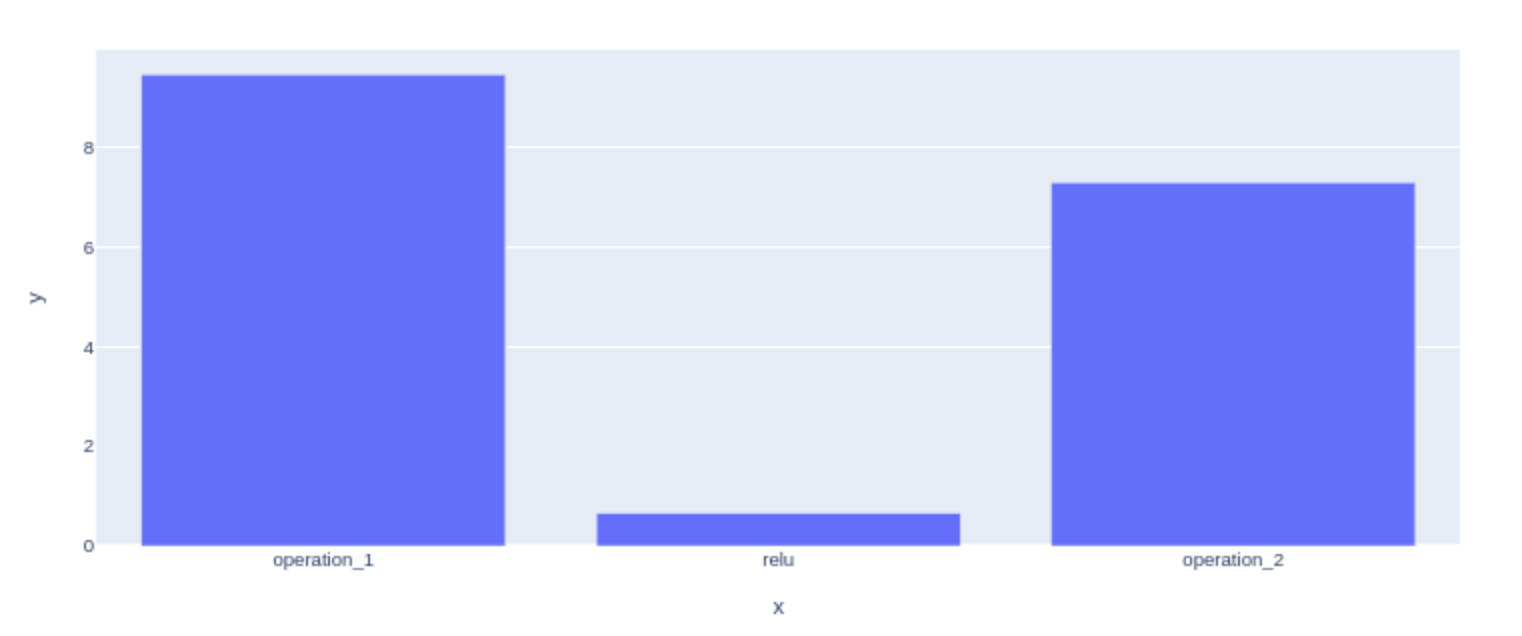
The difference is more pronounced with mixed precision enabled:
<picture 2 in the reply - the site only allows 1 image per post>
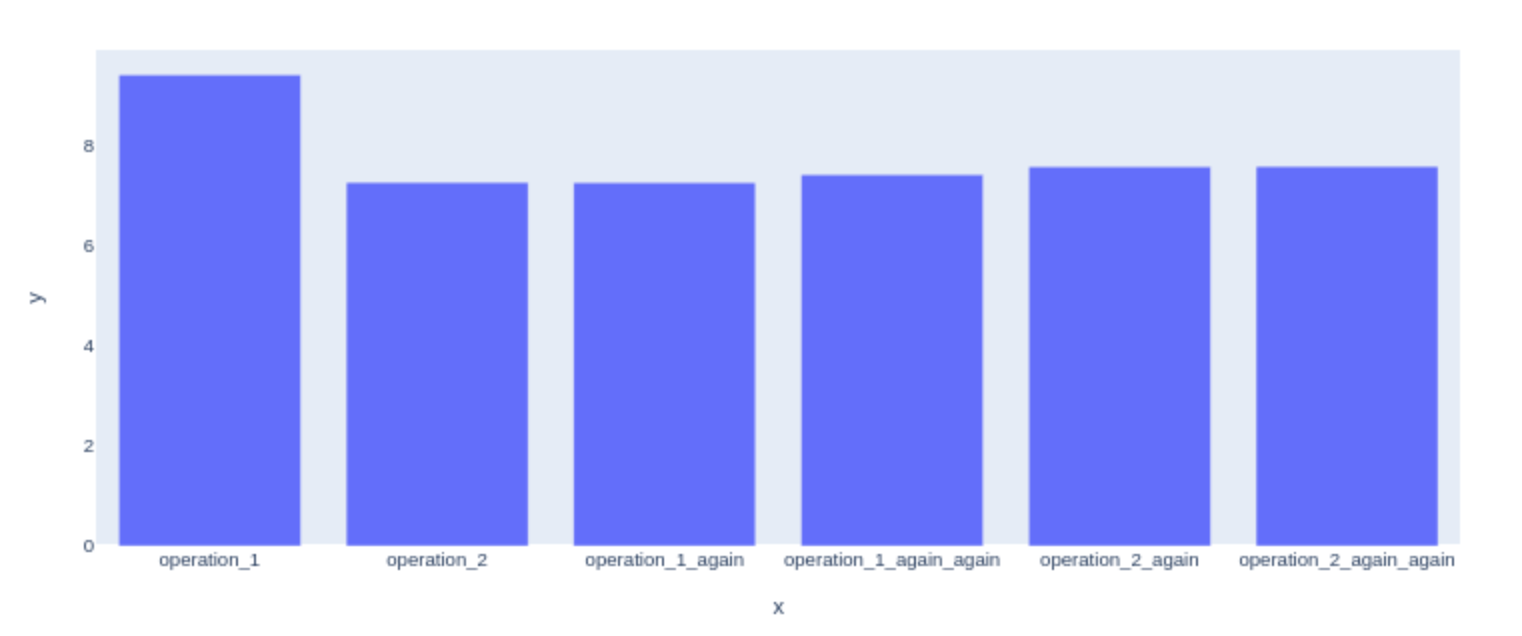
I then took to looking at what would happen if I followed the two operations with their repeated uses, i.e. operation1 → operation2 → operation1 → operation1 → operation2 → operation2
(relu omitted for brevity)
The results are as follows:
<picture 3 in the reply>
We can see that only the first operation execution takes more time.
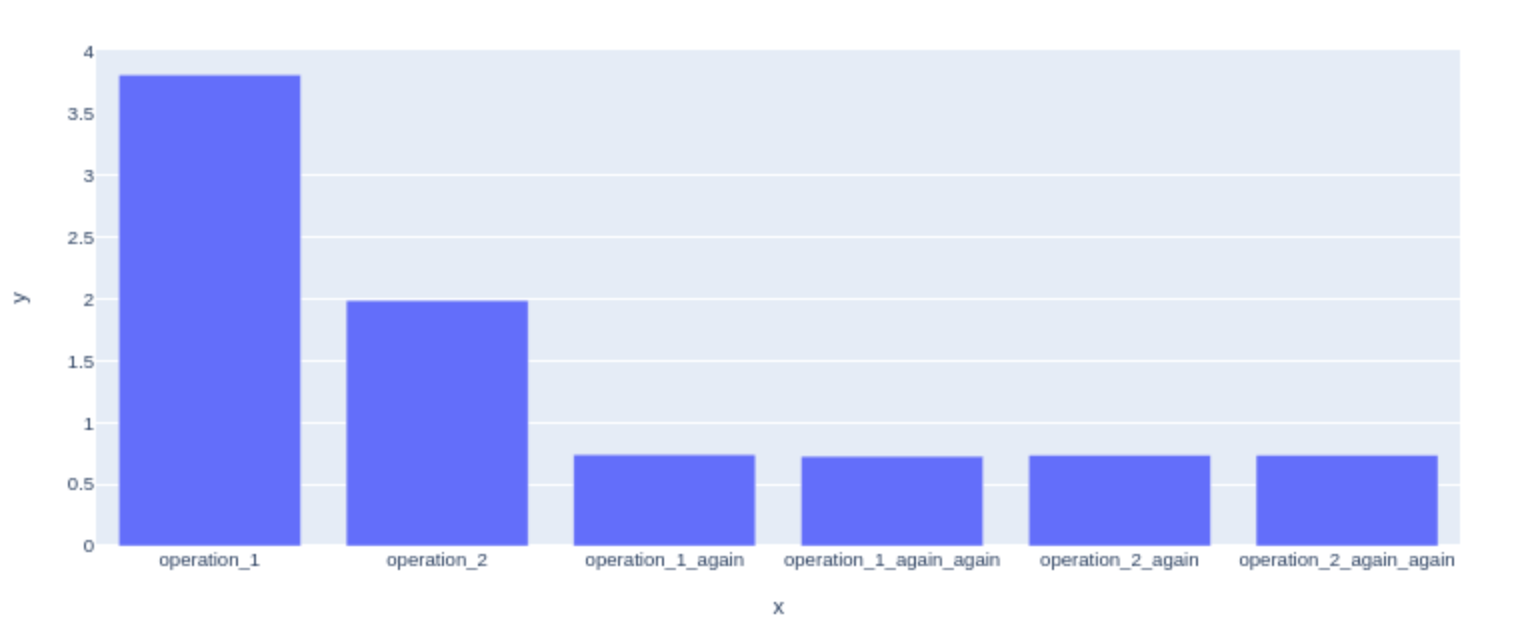
With mixed precision enabled, even more interesting things happen:
<picture 4 in the reply>
As we see, the first execution is the longest for a given operation, and the further ones all take the same amount of time.
I have two questions:
- Why are execution times different for the first use of
operation1andoperation2? - Why does mixed precision cause the repeated use of the same parameters to take less time to do the calculations?
My goal is to shorten the time for both operation1 and operation2, by bridging the gap between them and, if possible, getting them down to the time displayed in operation_1_again and operation_2_again.
The way I measure time is standard: i use cuda events for start and end of measurement, followed by torch.cuda.synchronise()
Any insights into inner workings of CUDA (I am using A100 80GB and PyTorch 2.0) and mixed precision intricacies would be greatly appreciated.