Alright so this looks like such a simple issue that I’m afraid I’ve misunderstood some of the core workings of PyTorch/autograd.
My problem is straightforward: I have a gradient of a sum that turns out 0 while it shouldn’t be, and it doesn’t match the sum of the gradients separately.
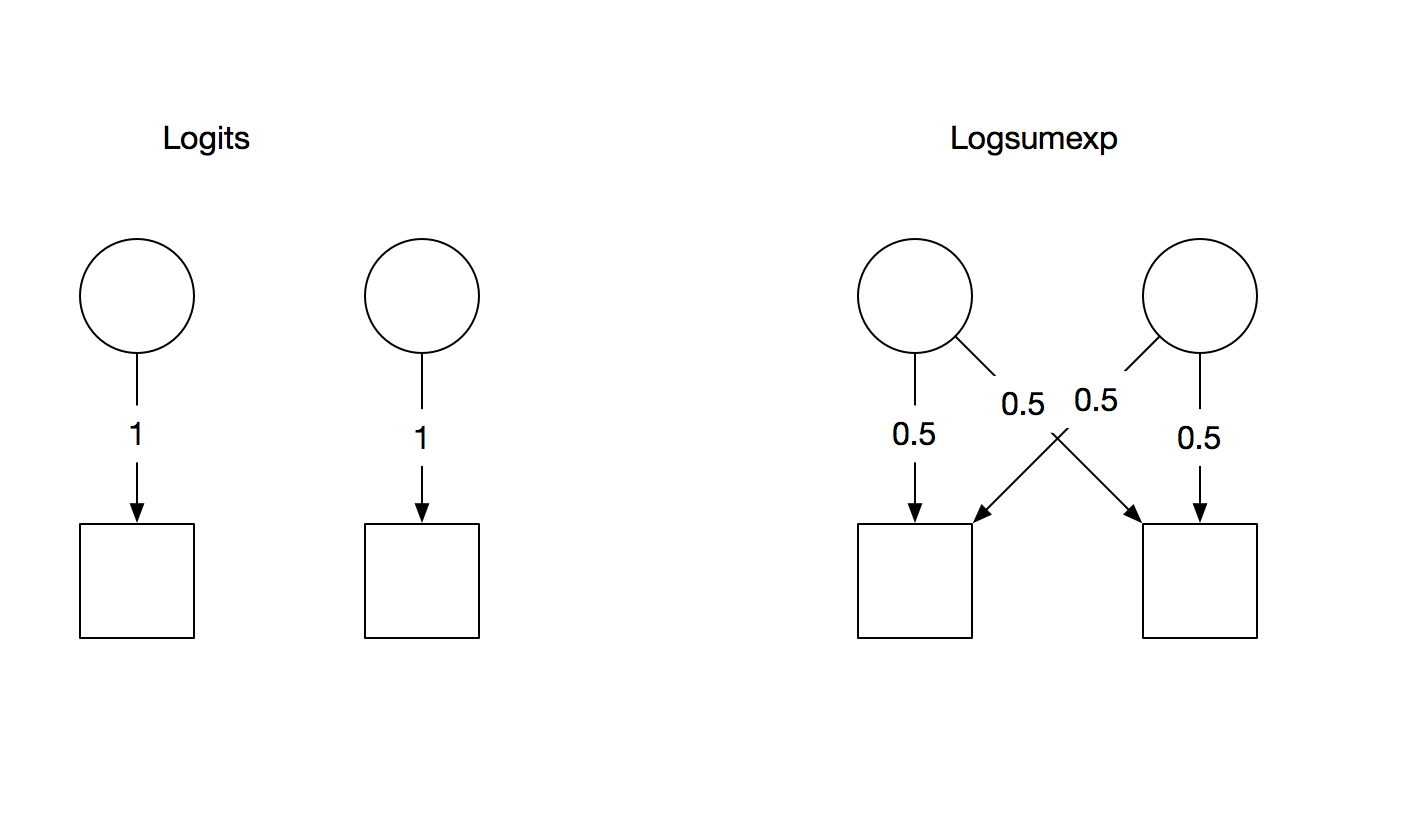
I’ve concocted a simplified example to illustrate. We’re in the probability domain, or rather, the logprob domain, so this is the straightforward approximation of probabilities using a softmax on top of a linear layer. Well, not quite a softmax, because logprobs. There are two output classes.
import torch
import torch.nn as nn
import torch.nn.functional as F
feat_dim, out_dim = 1, 2
encoder = nn.Linear(feat_dim, out_dim, bias=False)
nn.init.zeros_(encoder.weight.data)
# Fabricate some one-hot encoded data of batch size 1, good enough
batch_size = 1
input = torch.eye(feat_dim)[:batch_size]
As I said, I have the sum of gradients, or rather a difference really. Below I’ll show the gradients of the linear layer’s weights after backpropagating first the difference, then the summands themselves separately.
logits = encoder.forward(input)
norm = torch.logsumexp(logits, dim=1, keepdim=True)
(logits-norm).sum().backward()
print(encoder.weight.grad)
nn.init.zeros_(encoder.weight.grad.data)
logits = encoder.forward(input)
logits.sum().backward()
print(encoder.weight.grad)
nn.init.zeros_(encoder.weight.grad.data)
logits = encoder.forward(input)
norm = torch.logsumexp(logits, dim=1, keepdim=True)
norm.sum().backward()
print(encoder.weight.grad)
This gives (annotated):
# grad of logits - norm
tensor([[0.],
[0.]])
# grad of logits
tensor([[1.],
[1.]])
# grad of norm
tensor([[0.5000],
[0.5000]])
The gradients for logits and norm are exactly what I expected. I expected the gradient for logprobs to be the difference of the gradients of logits and norm, but that’s not the case. Instead it’s zeros, for no conceivable reason.
I must be missing something incredibly simple. Maybe the gradient of norm gets backpropagated multiple times, but I don’t see it. Could anyone shed some light on the issue?