Hi,
I’m trying to diagnose a performance discrepancy between using IterableDatasets and (map-style)Datasets in a multi-processed data loader setting.
My experiment (code at the end of the post) consisted of:
- Make a (Iterable)Dataset. This synthesizes dummy data and possibly adds a time delay to simulate batch loading work.
- Make a Dataloader that consumes the above dataset instance. The number of workers varied from 0 (loading in the main process) to 4.
- Iterate through 100 batches of data yielded by the dataloader, with possibly a time delay to simulate batch processing work (e.g. training).
I varied the number of workers, batch loading time, and batch processing time. I plotted my results as
IterableDataset (left) vs (map-style)Dataset (right)
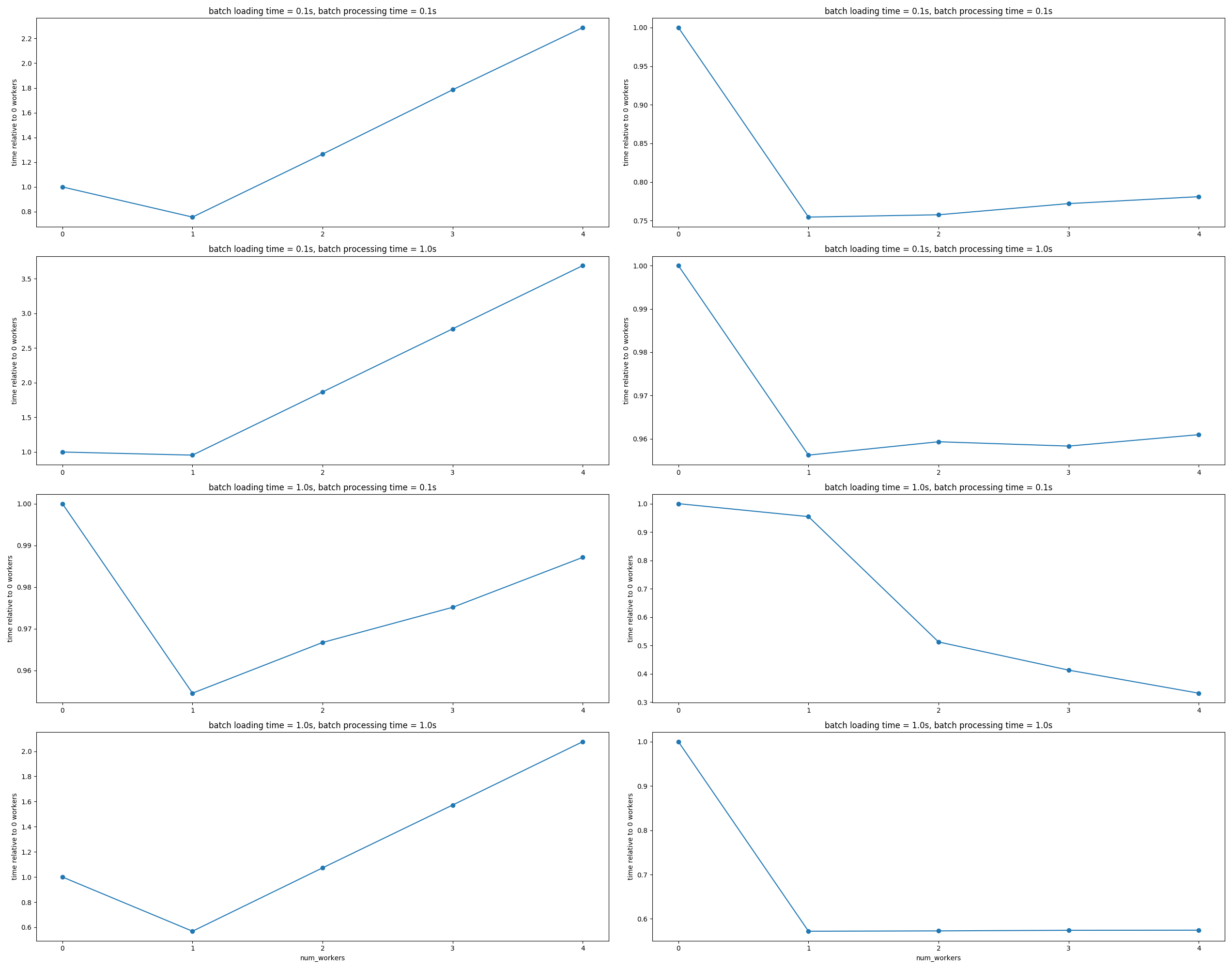
The vertical axis is time to run through N=100 batches divided by the time to do so with num_workers = 0 in each case. I grouped the results by batch processing / loading time.
I expected the behavior of (map-style)Datasets, but I did not expect a linear degradation in performance for num_workers >= 1 when using IterableDatasets.
Could someone please have a look at my code below and let me know if I’m using IterableDataset incorrectly or if there might be a bug we should know about/report?
Thanks,
Christos
import os
import time
import itertools
import numpy as np
import torch
class TimedBlock:
"""
Context manager to measure wall time.
"""
def __init__(self, name):
self.name = name
def __enter__(self):
self.t_start = time.perf_counter()
def __exit__(self, *args):
print("(%d) %s execution finished. Time elapsed = %.3fs." % (os.getpid(), self.name,
time.perf_counter() - self.t_start))
class IterableDataset(torch.utils.data.IterableDataset):
"""
Synthetic iterable dataset that simulates data loading work.
"""
def __init__(self, n_items, shape, batch_loading_time):
"""
Args:
n_items: number of items to return.
shape: shape of batch tensor to return.
batch_loading_time: each batch will take at least this many seconds to return.
"""
self.n_items = n_items
self.shape = shape
self.batch_loading_time = batch_loading_time
def __iter__(self):
self.i = 0
while self.i < self.n_items:
t_start = time.perf_counter()
X = np.random.randn(*self.shape)
t_remaining = self.batch_loading_time - (time.perf_counter() - t_start)
if t_remaining > 0:
time.sleep(t_remaining)
yield X
self.i += 1
class Dataset(torch.utils.data.Dataset):
"""
Synthetic map-style dataset that simulates data loading work.
"""
def __init__(self, n_items, shape, batch_loading_time):
"""
Args:
n_items: number of items to return.
shape: shape of batch tensor to return.
batch_loading_time: each batch will take at least this many seconds to return.
"""
self.n_items = n_items
self.shape = shape
self.batch_loading_time = batch_loading_time
def __len__(self):
return self.n_items
def __getitem__(self, idx):
t_start = time.perf_counter()
X = np.random.randn(*self.shape)
t_remaining = self.batch_loading_time - (time.perf_counter() - t_start)
if t_remaining > 0:
time.sleep(t_remaining)
return X
def test_simpleloader(n_iters=int(1e2), shape=(1,), num_workers=0, batch_loading_time=0, batch_process_time=0,
exp_name="simpleloader", dataset_cls=IterableDataset):
"""
Load and process n_iters batches of data using a dataloader and one of the above dataset classes. We simulate
training by waiting batch_process_time seconds per batch.
"""
dataset = dataset_cls(n_iters, shape, batch_loading_time)
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=None,
num_workers=num_workers,
collate_fn=None,
pin_memory=False,
worker_init_fn=None,
multiprocessing_context=None)
with TimedBlock(exp_name):
for i, x in enumerate(data_loader):
time.sleep(batch_process_time)
def simpleloader_grid(num_workers_grid=[0, 1, 2, 3, 4],
batch_loading_time_grid=[10**i for i in range(0, -2, -1)],
batch_process_time_grid=[10**i for i in range(0, -2, -1)],
dataset_cls=IterableDataset):
n_iters = int(1e2)
shape = (1,)
params = itertools.product(num_workers_grid, batch_loading_time_grid, batch_process_time_grid)
for p in params:
test_simpleloader(n_iters, shape, p[0], p[1], p[2], str(p), dataset_cls=dataset_cls)
if __name__ == "__main__":
torch.multiprocessing.set_start_method("spawn") # probably not important here
t_start = time.perf_counter()
simpleloader_grid(dataset_cls=IterableDataset)
print("Main execution time = %.3fs" % (time.perf_counter() - t_start))