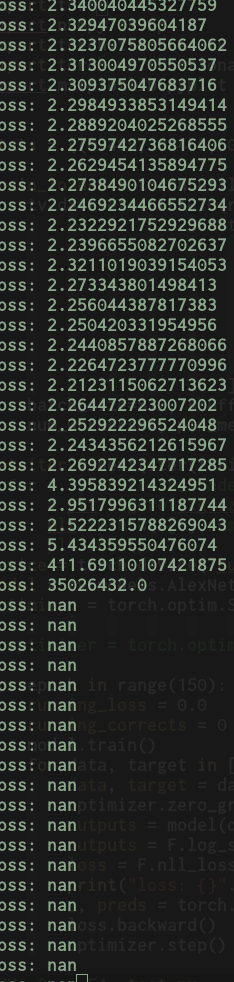
Can someone please shed some light on what’s going on here? Why do we get exploding loss leading to nan?
MWE:
import torch
import numpy as np
import torchvision as tv
import torch.nn.functional as F
stats = ((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
train_loader = torch.utils.data.DataLoader(
tv.datasets.CIFAR10(root='./data', train=False,
transform=tv.transforms.Compose([
tv.transforms.Resize(64), tv.transforms.ToTensor(), tv.transforms.Normalize(*stats)
]), download=True),
batch_size=512, shuffle=True,
num_workers=4, pin_memory=False)
dataiter = next(iter(train_loader))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = tv.models.AlexNet(num_classes=10).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, weight_decay=5e-4, momentum=0.9, nesterov=True)
for epoch in range(150):
model.train()
for data, target in [dataiter] * 50:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(data)
outputs = F.log_softmax(outputs, dim=1)
loss = F.nll_loss(outputs, target)
print("loss: {}".format(loss.item()))
probs, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()