Hello,
This has appeared both on the forums and in PyTorch issues before (this one is still open). Nevertheless, I still find that when training a “simulated” Conv2d using Unfold, Transpose, Linear, Transpose, Fold, the gradients are different to using just the “equivalent” Conv2d.
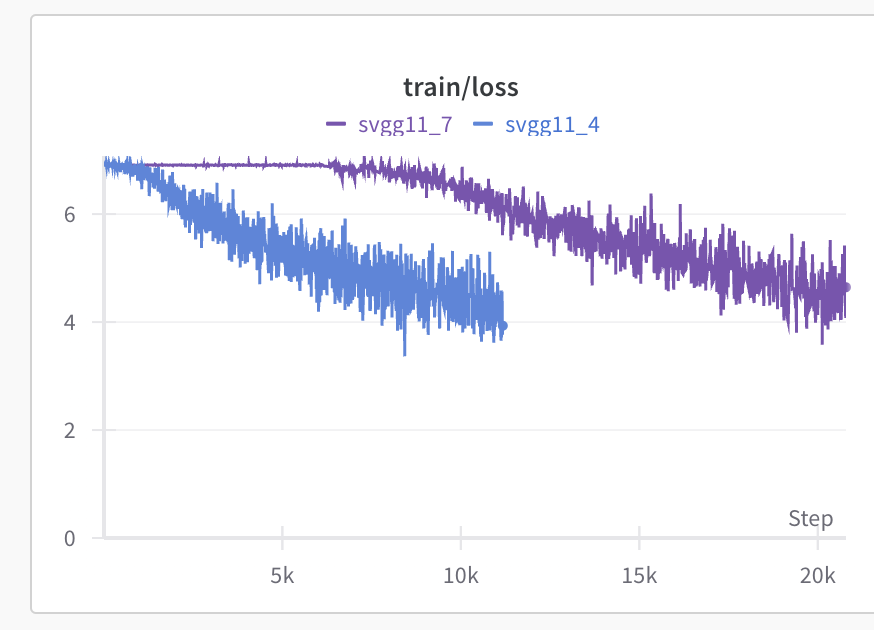
For a reproducible example, I provide a “simulated” VGGxx implementation and loss curves from corresponding runs (all parameters being equal).
To get the simulated VGG, copy the contents of the torchvision implementation and modify make_features as follows:
def make_layers(cfg: List[Union[str, int]], batch_norm: bool = False) -> nn.Sequential:
layers: List[nn.Module] = []
in_channels = 3
pooling_depth: int = 0
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
pooling_depth += 1
else:
v = cast(int, v)
w, h = 224 // (2**pooling_depth), 224 // (2**pooling_depth)
layers += [ nn.Unfold(kernel_size=3, padding=1, stride=1) ]
layers += [ Transpose(-1, -2) ]
layers += [ nn.Linear(in_channels * 3*3, v, bias=True) ]
layers += [ nn.ReLU(inplace=True) ]
layers += [ Transpose(-1, -2) ]
# layers += [ Reshape(-1, v, w, h) ]
layers += [ nn.Fold(output_size=(w, h), kernel_size=1, stride=1) ]
in_channels = v
return nn.Sequential(*layers)
The training harness used is the one of torchvision/classification, and I follow the recipe given in the README.
Here are the losses for the first few epochs of VGG11 reference (blue) and simulated (yellow):
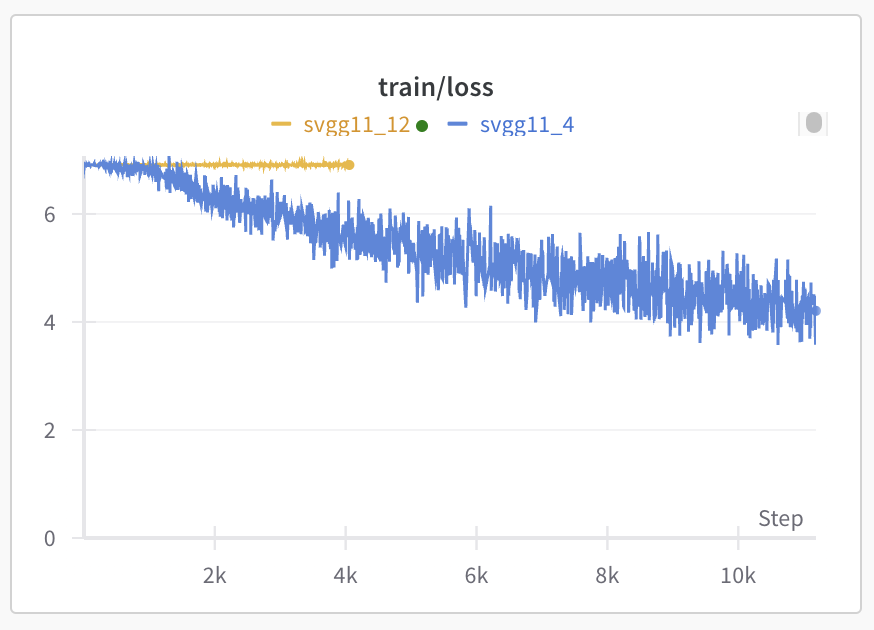
Note that I also tried training both in double precision and it didn’t make a difference.
Am I missing something, or is there genuinely a bug in Unfold/Fold backward pass?