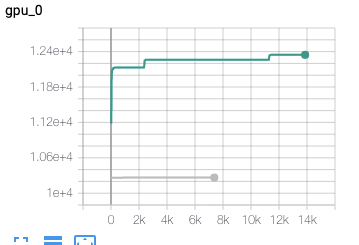
I am training pytorch model with Contrastive Loss (pytorch-metric-learning) and there are two ways I can batch text examples. In the first method, I am padding only up to maximal sequence length in a batch. In the second case, I am padding always up to 510 tokens no matter what the sequence size is. In general, tensor size in the first method is always smaller or equal to the second method. Yet, what I am observing is that smaller batch (the whole training) is actually consuming more memory than the constant, larger batch. Additionally, it produces CUDA out of memory error at some point in training (during a backward call). Green line in the Figure corresponds to memmory consumption for a smaller, dynamic batch. Grey curve for larger, constant size batch. I would expect an inverse situation. What is going on? How to even debug this kind errors?
I am training with pytorch-lightning, pytorch==1.5.0 and amp O2 (cuda memory also shows up without amp)