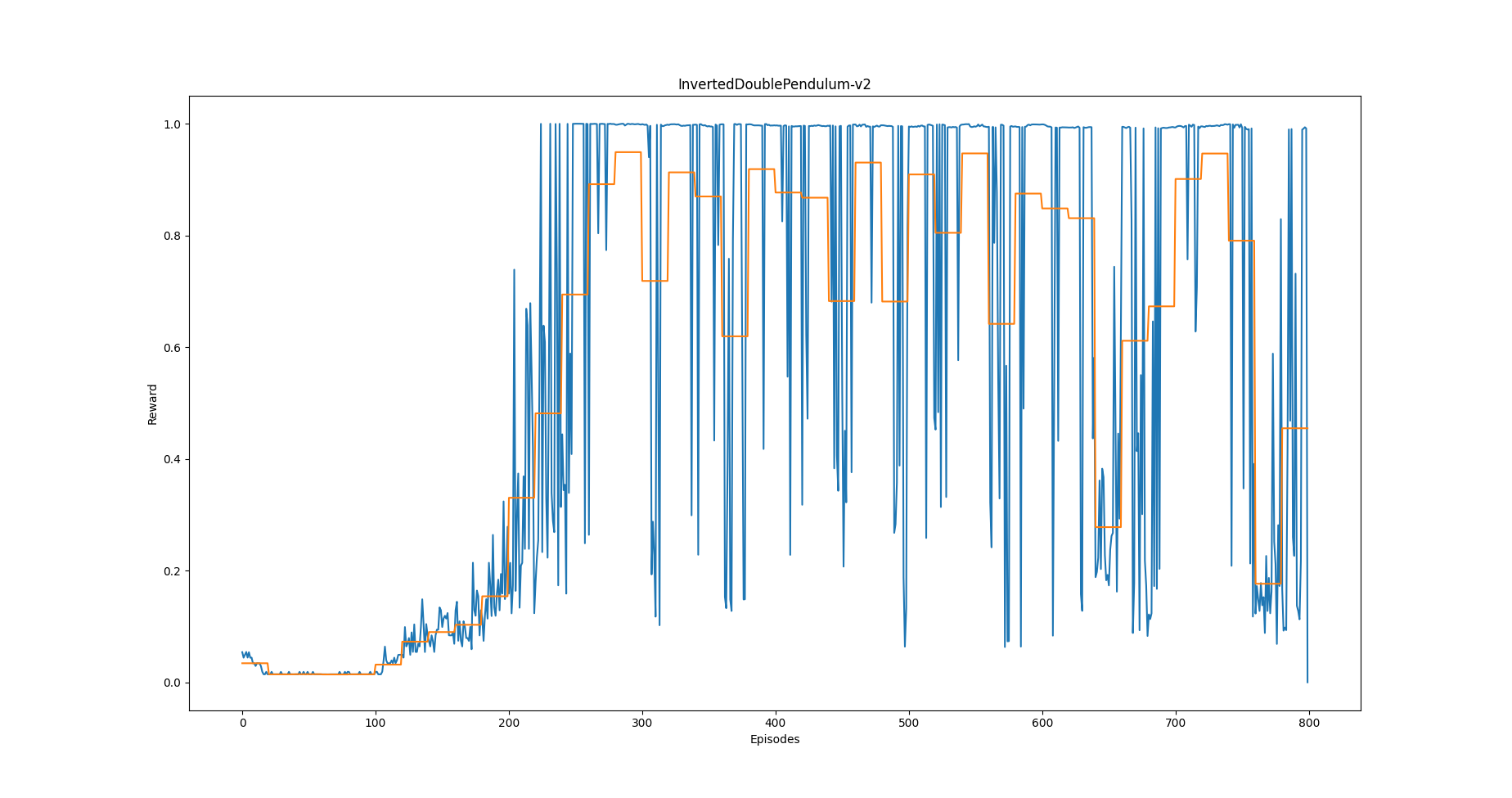
Hi, I’m trying to implement ddpg from scratch, following Lillicrap’s original paper (https://arxiv.org/pdf/1509.02971.pdf). I’m having problems with the stability of the learning, and I really don’t know how to solve this problem. I tried different values for tau (parameter for target nets soft update), learning rate, batch size and dimension of actor and critic networks. I tried the algorithm on different mujoco envs too, and the results are almost the same you can see in the picture. Da you have any suggestion? Thanks in advance.