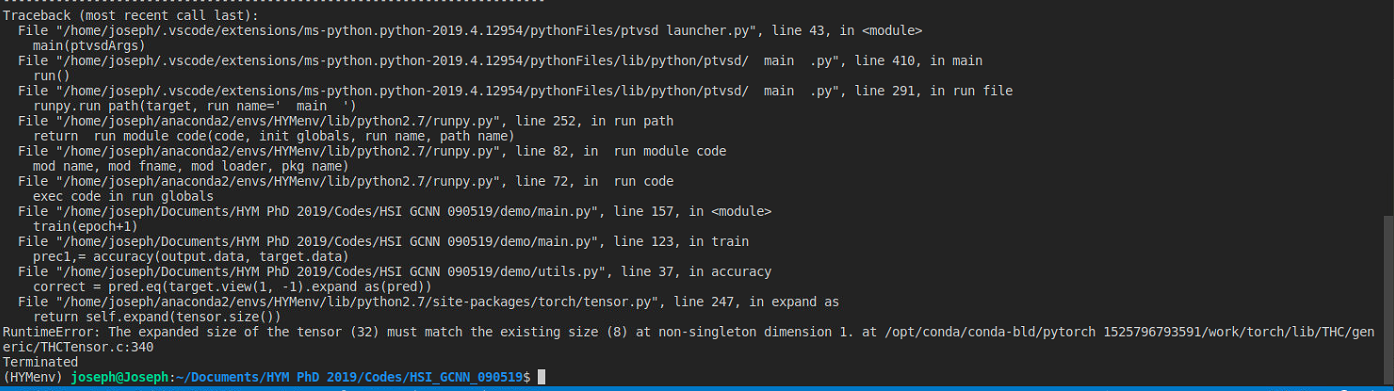
I have got this error while running my code, the tensor shape is (BatchXchannelsXHightXWidth) [8,204,15,15],
However, it worked perfectly for the same image with different height and width [8,204,11,11].
Thanks in advance
I have got this error while running my code, the tensor shape is (BatchXchannelsXHightXWidth) [8,204,15,15],
However, it worked perfectly for the same image with different height and width [8,204,11,11].
Thanks in advance
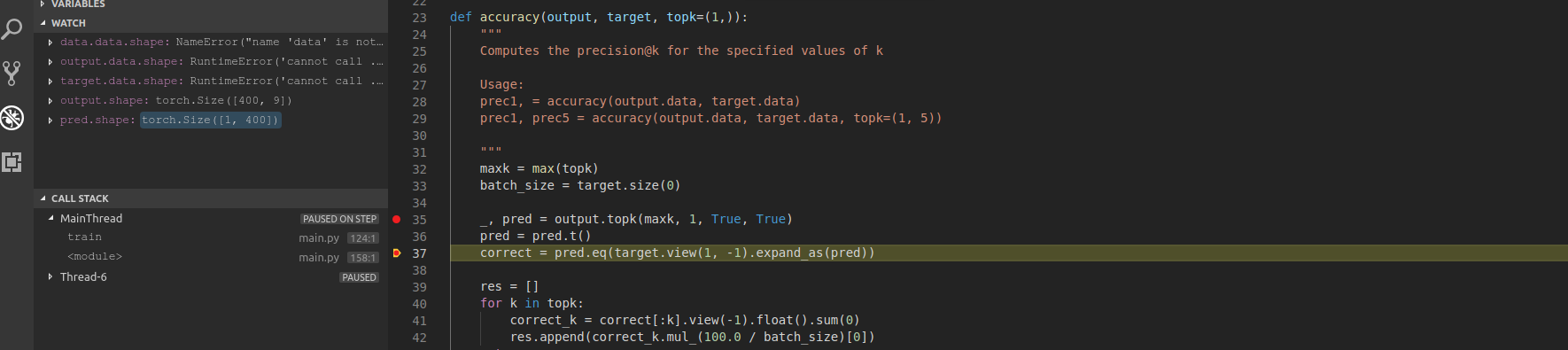
Could you post the shapes of target and pred before trying to calculate correct?
Any suggestion to solve it !?
I’m not sure, why the target and pred tensors have such a different shape.
Could you explain your use case a bit and how the predictions correspond to the target?
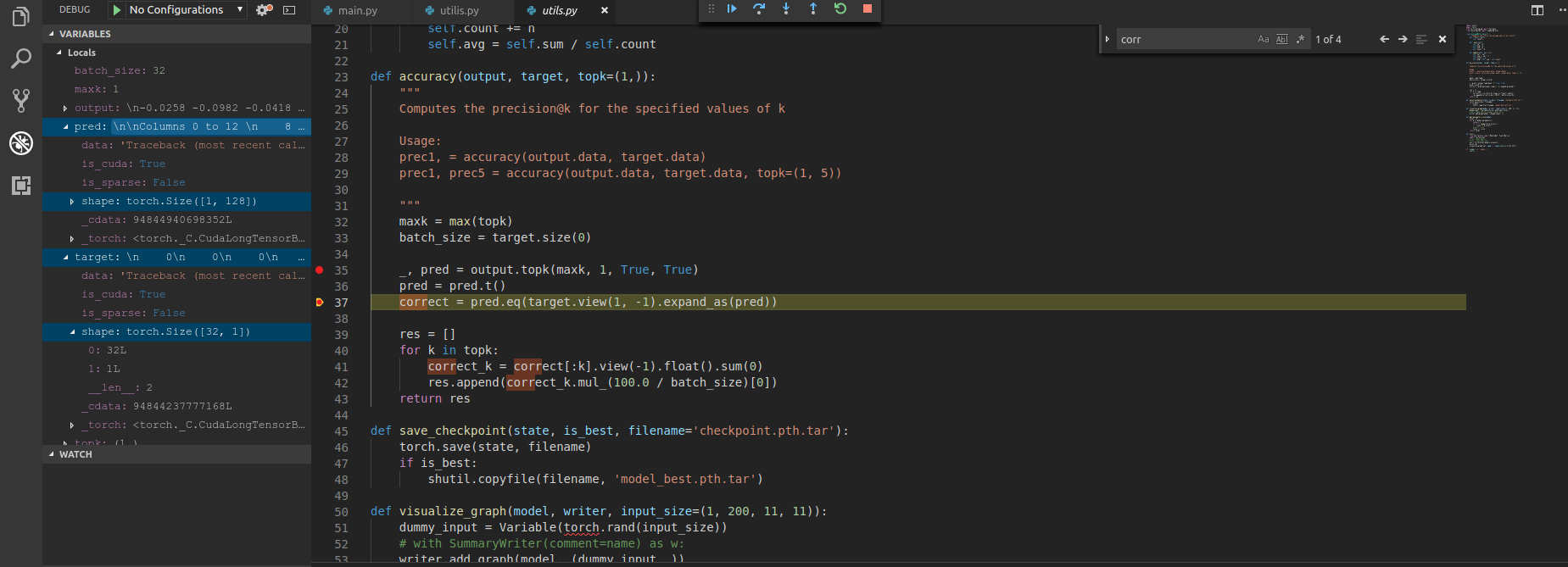
The original datasets size is [103x11x11] or [103x15x15] same datasets just different image sizes, it has 9 classes.
In “Train()” you can see the size of both tensors "output [400 9] , after FC.layer " & “target [32 1] which is [batchSz 1]”
self.ap = nn.AvgPool2d(2)
self.fc1 = nn.Linear('***', 1024) '***: i don't know what to set as an input here '
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(1024, 9 )
def forward(self, x):
x = self.model(x)
x = self.ap(x)
x = x.view("**", -1) " **: i wanna make it [batch_size -1] "
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
@ptrblck Thanks for your help 
Add a print statement in your forward method so see the shape of x:
def forward(self, x):
x = self.model(x)
x = self.ap(x)
x = x.view(x.size(0), -1)
print(x.shape)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
and just set the in_features of self.fc1 to a temporary number.
After the first forward pass, use the printed shape to set the number of input features for your linear layer.
Alternatively you could also calculate the feature size using the whole model architecture.
Also, if you are dealing with varying sized inputs, you might want to add an adaptive pooling layer, which will always yield the same output size.
I have got this error while running my code
Traceback (most recent call last):
File "train.py", line 622, in <module>
train(hyp, opt, device, tb_writer, wandb)
File "train.py", line 79, in train
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc).to(device) # create
File "/content/drive/MyDrive/yolov3_v0/models/yolo.py", line 97, in __init__
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s),torch.zeros(1, ch, s, s))]) # forward
File "/content/drive/MyDrive/yolov3_v0/models/yolo.py", line 174, in forward
out = self.model[32:33](torch.unsqueeze((out6),dim=0))
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/container.py", line 119, in forward
input = module(input)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/content/drive/MyDrive/yolov3_v0/models/yolo.py", line 50, in forward
out[i] = self.m[i](out[i]) # conv
RuntimeError: The expanded size of the tensor (256) must match the existing size (27) at non-singleton dimension 1. Target sizes: [1, 256, 32, 32]. Tensor sizes: [27, 32, 32]
and my code :
out_rgb = self.model[0:3](in_rgb)
print("out_rgb", out_rgb.shape)
out_ther = self.model[3:6](in_ther)
print("out_ther", out_ther.shape)
in_cat = self.model[6:7]((out_rgb,out_ther))
print("in-cat", in_cat.shape)
out11 = self.model[7:11](in_cat)
print("out11", out11.shape)
out1 = self.model[11:13](out11)
print("out1", out1.shape)
out2 = self.model[13:22](out1)
print("out2", out2.shape)
out3 = self.model[22:23]((out1,out2))
print("out3", out3.shape)
out4 = self.model[23:29](out3)
print("out4",out4.shape)
out_cat3 = self.model[22:23]((out11,out4))
print("out_cat3", out_cat3.shape)
out5 = self.model[29:30](torch.unsqueeze((out_cat3),dim=0))
print("out5",out5.shape)
out6 = self.model[30:32](out5)
print("out6",out6.shape)
out = self.model[32:33](torch.unsqueeze((out6),dim=0))
print("out",out.shape)
return output
Shapes :
out_rgb torch.Size([1, 64, 128, 128])
out_ther torch.Size([1, 64, 128, 128])
in-cat torch.Size([1, 128, 128, 128])
out11 torch.Size([1, 256, 32, 32])
out1 torch.Size([1, 512, 16, 16])
out2 torch.Size([1, 256, 16, 16])
out3 torch.Size([1, 768, 16, 16])
out4 torch.Size([1, 128, 32, 32])
out_cat3 torch.Size([1, 384, 32, 32])
out5 torch.Size([1, 384, 32, 32])
out6 torch.Size([1, 256, 32, 32])
Thanks in advance
Based on the error message it seems you are trying to expand a tensor with an invalid shape.
This code snippet would reproduce the issue:
x = torch.randn(27, 32, 32)
y = x.expand(1, 256, 32, 32)
> RuntimeError: The expanded size of the tensor (256) must match the existing size (27) at non-singleton dimension 1. Target sizes: [1, 256, 32, 32]. Tensor sizes: [27, 32, 32]
You could check your model implementation for these expand calls and make sure it’s using a valid shape.