Hi,
I’m completely new to pytorch. So I was learning using pytorch using this tutorial. But I’m using different datasets for modeling.
The code I’m using is the following:
import os, sys, glob
from PIL import Image
import skimage
import skimage.io
import numpy as np
import torch
from torch.autograd import Variable
from torch import optim
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import train_test_split
class ConvNet(torch.nn.Module):
def __init__(self, output_dim):
super(ConvNet, self).__init__()
self.conv = torch.nn.Sequential()
self.conv.add_module("conv_1", torch.nn.Conv2d(3, 299, kernel_size=5))
self.conv.add_module("maxpool_1", torch.nn.MaxPool2d(kernel_size=2))
self.conv.add_module("relu_1", torch.nn.ReLU())
self.conv.add_module("conv_2", torch.nn.Conv2d(299, 50, kernel_size=5))
self.conv.add_module("dropout_2", torch.nn.Dropout())
self.conv.add_module("maxpool_2", torch.nn.MaxPool2d(kernel_size=2))
self.conv.add_module("relu_2", torch.nn.ReLU())
self.fc = torch.nn.Sequential()
self.fc.add_module("fc1", torch.nn.Linear(320, 50))
self.fc.add_module("relu_3", torch.nn.ReLU())
self.fc.add_module("dropout_3", torch.nn.Dropout())
self.fc.add_module("fc2", torch.nn.Linear(50, output_dim))
def forward(self, x):
x = self.conv.forward(x)
x = x.view(-1, 320)
return self.fc.forward(x)
def train(model, loss, optimizer, x_val, y_val):
x = Variable(x_val, requires_grad=False)
y = Variable(y_val, requires_grad=False)
# Reset gradient
optimizer.zero_grad()
# Forward
fx = model.forward(x)
output = loss.forward(fx, y)
# Backward
output.backward()
# Update parameters
optimizer.step()
return output.data[0]
def predict(model, x_val):
x = Variable(x_val, requires_grad=False)
output = model.forward(x)
return output.data.numpy().argmax(axis=1)
def main():
## Get the location of the image and list of class
img_data_dir = "Animal_Data"
## Get the contents in the image folder. This gives the folder list of each image "class"
contents = os.listdir(img_data_dir)
## This gives the classes of each folder. We will use these classes to classify each image type
classes = [each for each in contents if os.path.isdir(img_data_dir + "/" + each)]
batch = [] ## Empty list of image list
labels = [] ## Empty image labels list
for each in classes: ## looping over each class
class_path = img_data_dir + "/" + each ## create the path of each image class
files = os.listdir(class_path) ## list of all files in each image class folder
for ii, file in enumerate(files, 1): ## Enumerate over each image list
img = skimage.io.imread(os.path.join(class_path, file)) ## each the images from the folder. We are passing the file path + name in "imread"
img = img / 255.0 ## standardize the data
batch.append(img.reshape(1, 299, 299, 3)) ## reshaping images and append in one file list
labels.append(each) ## appending the labels of each image
labels = [1.0 if i == 'Leopard' else 0 for i in labels]
trX, teX, trY, teY = train_test_split(batch, labels, test_size=0.2, random_state=0)
trX = np.asarray(trX)
trX = np.squeeze(trX, axis = 1)
teX = np.asarray(teX)
teX = np.squeeze(teX, axis = 1)
trY = np.asarray(trY)
trX = torch.from_numpy(np.stack(trX)).float()
teX = torch.from_numpy(np.stack(teX)).float()
trY = torch.from_numpy(trY).long()
n_examples = len(trX)
model = ConvNet(output_dim=2)
loss = torch.nn.CrossEntropyLoss(size_average=True)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
batch_size = 100
for i in range(20):
cost = 0.
num_batches = n_examples // batch_size
for k in range(num_batches):
start, end = k * batch_size, (k + 1) * batch_size
cost += train(model, loss, optimizer, trX[start:end], trY[start:end])
predY = predict(model, teX)
print("Epoch %d, cost = %f, acc = %.2f%%"
% (i + 1, cost / num_batches, 100. * np.mean(predY == teY)))
if __name__ == "__main__":
main()
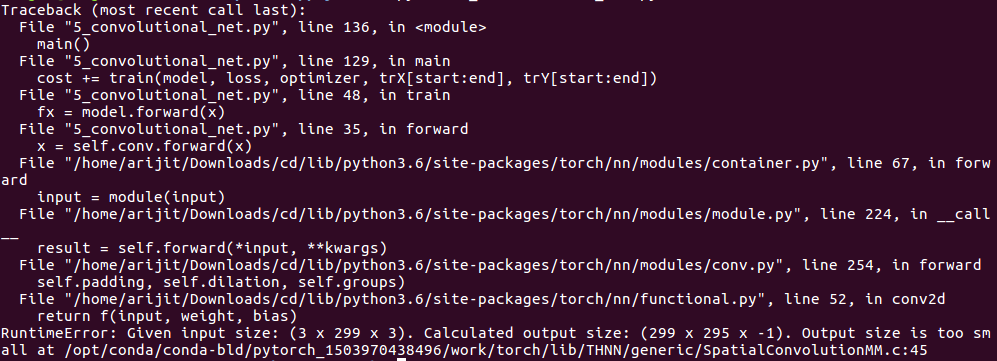
But I’m getting the following error:
I’m having hard to understand the torch.nn.Conv2d structure. The document says, first input is channel and then output level. This tread is saying output level can be anything. But still I’m getting the error. Typically we calculate output level as (W−F+2P)/S+1, where W is width of the image, F is filter size, P is padding and S is stride. Not sure how we can do it in pytorch.
Thank you!