Hello I am getting the following warning:
/home/nicofish/.local/lib/python3.8/site-packages/torch/nn/modules/loss.py:446: UserWarning: Using a target size (torch.Size([32])) that is different to the input size (torch.Size([32, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
return F.mse_loss(input, target, reduction=self.reduction)
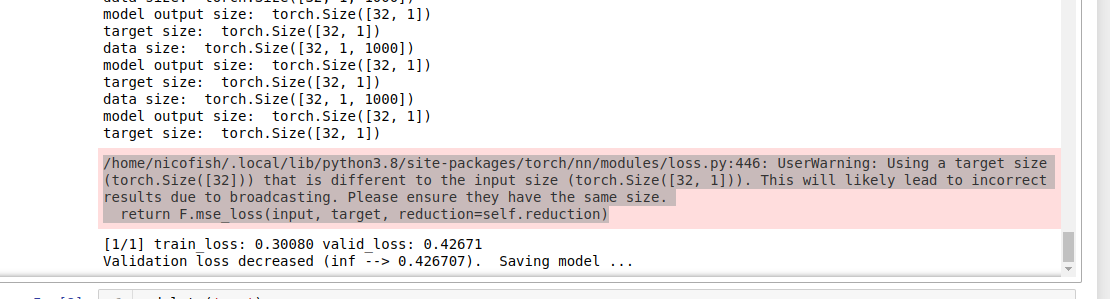
I printed my target size dimensions as well as the model output dimensions and they are the same. I included a screen shot of my print below. As you can see the target as well as the model output which go to my criterion = nn.MSELoss() have the same dimensions. Is this a bug or is there another reason why this is happening?
I should add that the model is training perfectly fine and works well.
Here is my training function in case it helps with debugging.
#function used to train the model
#function modified from:
#see: https://github.com/Bjarten/early-stopping-pytorch
def train_model_task1(model, train_loader, test_loader, valid_loader, batch_size, patience, n_epochs, device = 'cpu', learn_rate = .001):
#print('DEVICE: ', device)
#modified from: https://github.com/Bjarten/early-stopping-pytorch/blob/master/MNIST_Early_Stopping_example.ipynb
# to track the training loss as the model trains
train_losses = []
# to track the validation loss as the model trains
valid_losses = []
# to track the average training loss per epoch as the model trains
avg_train_losses = []
# to track the average validation loss per epoch as the model trains
avg_valid_losses = []
# initialize the early_stopping object
early_stopping = EarlyStopping(patience=patience, verbose=True)
#set criterion and optimizer
criterion = nn.MSELoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=learn_rate)
for epoch in range(1, n_epochs + 1):
###################
# train the model #
###################
model.train() # prep model for training
for batch, dat in enumerate(train_loader, 1):
data = dat[0].to(device).float()#must be float
#must unsqueeze to have shape [batch_size, 1] cause shape [batch_size depreciated]
target = dat[1].to(device).unsqueeze(1).float()#must cast to float not long cause not integer
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
#print('made it past model in put')
# calculate the loss
print('data size: ', data.size())
print('model output size: ', output.size())
print('target size: ', target.size())
loss = criterion(output, target) #####USER WARNING IS TRIGGERED HERE I THINK####
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# record training loss
train_losses.append(loss.item())
######################
# validate the model #
######################
model.eval() # prep model for evaluation
for dataV, targetV in valid_loader:
# forward pass: compute predicted outputs by passing inputs to the model
output = model(dataV.to(device).float())
# calculate the loss
loss = criterion(output, targetV.to(device).long())
# record validation loss
valid_losses.append(loss.item())
# print training/validation statistics
# calculate average loss over an epoch
train_loss = np.average(train_losses)
valid_loss = np.average(valid_losses)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)
epoch_len = len(str(n_epochs))
print_msg = (f'[{epoch:>{epoch_len}}/{n_epochs:>{epoch_len}}] ' +
f'train_loss: {train_loss:.5f} ' +
f'valid_loss: {valid_loss:.5f}')
print(print_msg)
# clear lists to track next epoch
train_losses = []
valid_losses = []
# early_stopping needs the validation loss to check if it has decresed,
# and if it has, it will make a checkpoint of the current model
early_stopping(valid_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break
#clear optimizer one more time
optimizer.zero_grad()
# load the last checkpoint with the best model
model.load_state_dict(torch.load('checkpoint.pt'))
return model, avg_train_losses, avg_valid_losses```
I appreciate any help