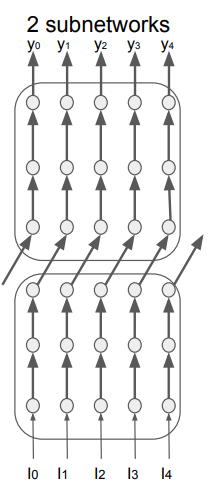
I have 2 of the same GPU and I want to achieve faster processing by utilizing both of them. However, I am doing this in a different way, imitating the idea of Massively Parallel Video Networks:
I have divided my model into two sub-models. I want to run them concurrently, one part processing the input video frame by frame, and the other processing the output of the first one. However, there is a catch. When the first sub-model returns an output, it passes it to the second sub-model and starts processing the next frame of the input. By utilizing both the GPUs the authors of the paper achieve faster processing. Any idea on how to do this? The figure shows the idea: (the network is unrolled over time)
The idea is not the same as nn.DataParallel(). I have tried torch.multiprocessing, DistributedDataParallel() but I am having trouble understanding how to do this.
Thanks for your reply and sorry for my late reply. I will look into these methods. I am only doing this for the test phase, so I will only have to transfer one tensor per input frame to processor 2.
If anybody else has some further suggestions, I will be happy to hear them!
Thank you. I have seen this tutorial previously, however, the model parallel part is not what I want. For the pipelining part, I am having trouble how that part is getting executed. If you can further clarify that part for me, that would be great.
Did you find a solution?
I have the same problem and need to seperate my model into parts and load them on 2 GPUs. But the second part is a frozen LLM and it doesn’t require grad.