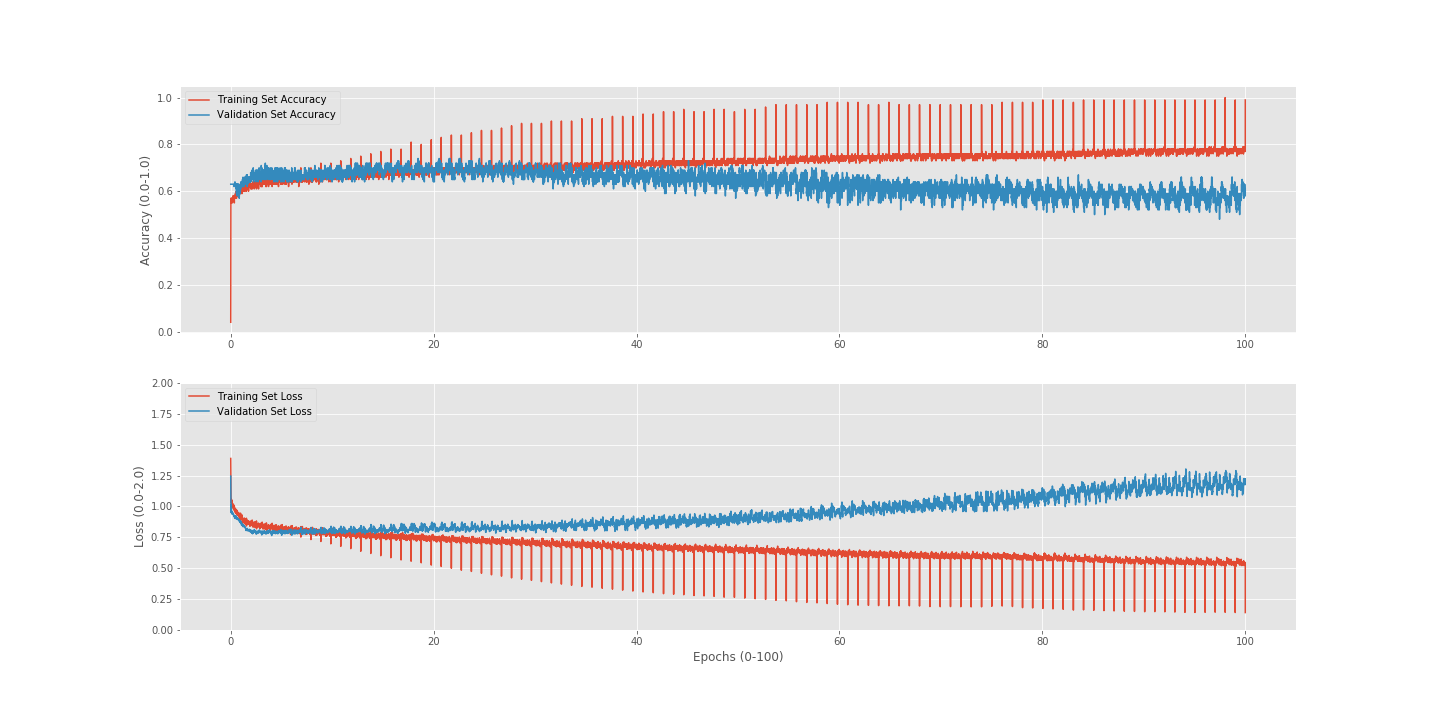
I am using a sampler to try and counteract the model overfitting to one class in the model. However, I think I might be doing it wrong because the results from using a dataset that had balanced classes were better than using the unbalanced dataset and weighted classes (assuming I did it right and the unbalanced data set had nearly 50x more data in it). Also, I am wondering what are causing the increasing spikes in the training set? something with the way the Adam optimizer optimizes?
If you are dealing with an imbalanced dataset and try to weight the loss function or use weighted sampling, you would usually trade the TRP for the FPR or vice versa. I would expect your accuracy to be higher in general for a balanced dataset.
I assume the spikes come from the order of your passed data.
Could you shuffle the data and check, if the spikes are still present?
What is TRP, and FPR? What do you think is causing the accuracy in my balanced data is be lower than expected? Do you think this might have to do with my net (its pretty shallow)? I am augmenting all my data with resampling, and random zero bursts, have any other suggestion?
Network:
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv1d(1, 45, 4)
self.conv2 = nn.Conv1d(45, 90, 4)
self.conv3 = nn.Conv1d(90, 180, 4)
x = torch.randn(1,1,180).view(-1,1,180)
self._to_linear = None
self.convs(x)
self.fc1 = nn.Linear(self._to_linear, 180)
self.fc2 = nn.Linear(180, 4)
def convs(self, x):
x = F.max_pool1d(F.relu(self.conv1(x)), 2) # adjust shape of pooling?
x = F.max_pool1d(F.relu(self.conv2(x)), 2) # x = F.max_pool1d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool1d(F.relu(self.conv3(x)), 2)
if self._to_linear is None:
self._to_linear = x[0].shape[0]*x[0].shape[1]
return x
def forward(self, x):
x = self.convs(x)
x = x.view(-1, self._to_linear) # .view is reshape ... this flattens X before
x = F.relu(self.fc1(x))
x = self.fc2(x) # bc this is our output layer. No activation here.
return x
net = Net().to(device)
print(net)
I am currently working on running the model to see if it changes the spikes.
TPR and FPR (sorry for the typo) refer to the True Positive Rate and True Negative Rate.
Note that the accuracy might be misleading for an imbalanced dataset, as described in the Accuracy Paradox.
The spikes in the training set went way after reprocessing the dataset and training the model off of the newly processed training set, but the spikes did not go away after shuffling the data.
Then it seems that the unbalanced dataset still preforms less than the balanced dataset in terms of loss.
How did you process the data that the spikes went away?
Based on your initial post, you are dealing with the ratio of 50:1 in your imbalanced dataset.
As I explained, the accuracy might be misleading for it and you should get a ~98% accuracy if your model just outputs the majority class.
I don’t remember changing anything during the process, I just processed the data again from the raw data.
Also, I don’t think I mentioned this, but I have 4 classes 56:11:30:3.
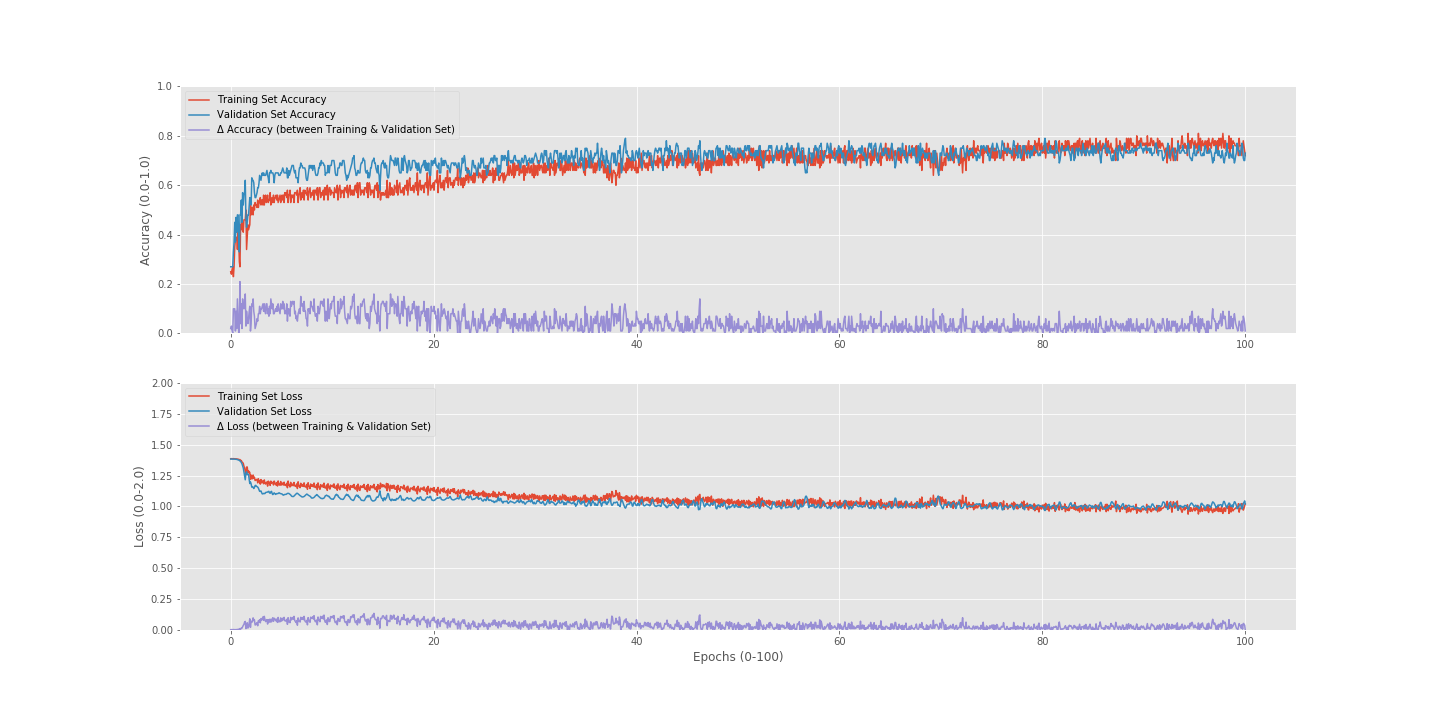
I since have moved away from and unbalanced dataset, and still am achieving a 60% accuracy. Fine tuning the model could yield at the most 10% in valuation accuracy correct (is accuracy an accurate way of measuring the success in a model when using a balanced dataset)? If this is true, I think my problem with the accuracy/loss might be with my dataset.
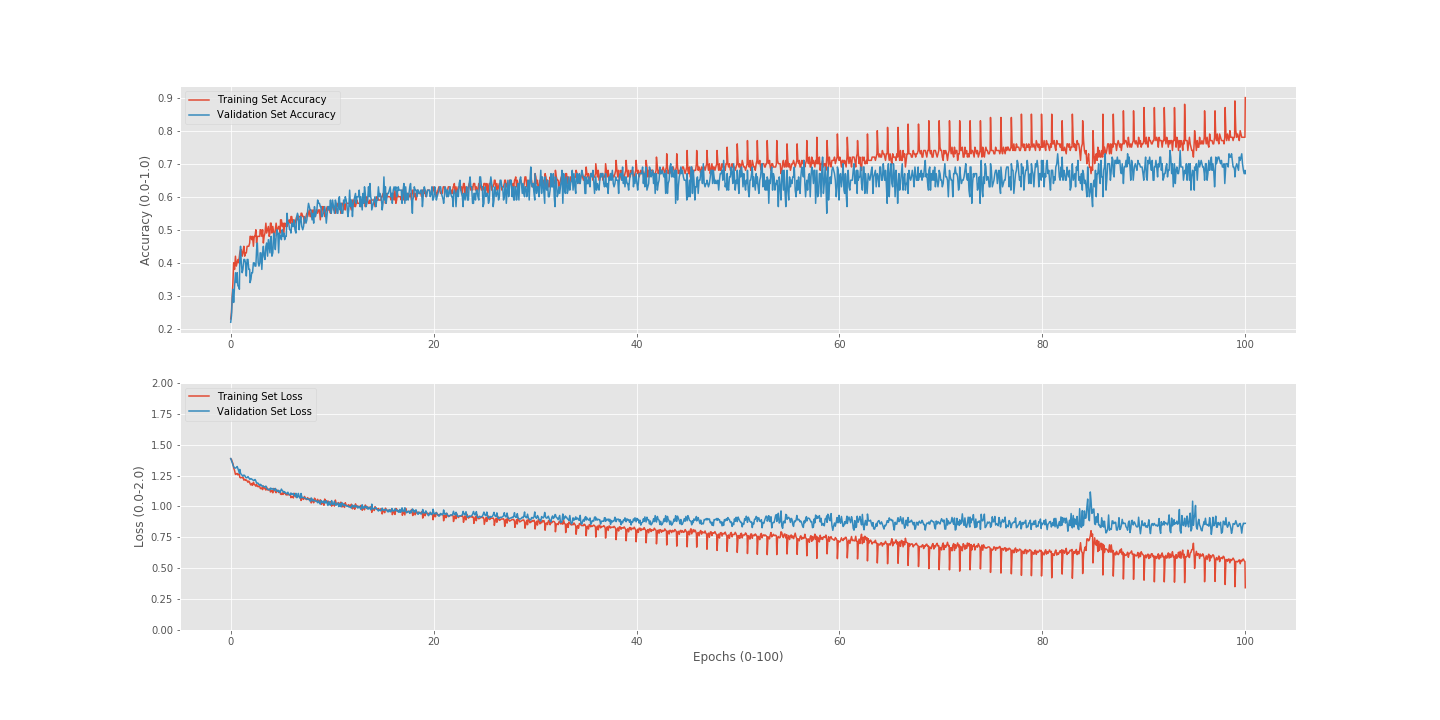
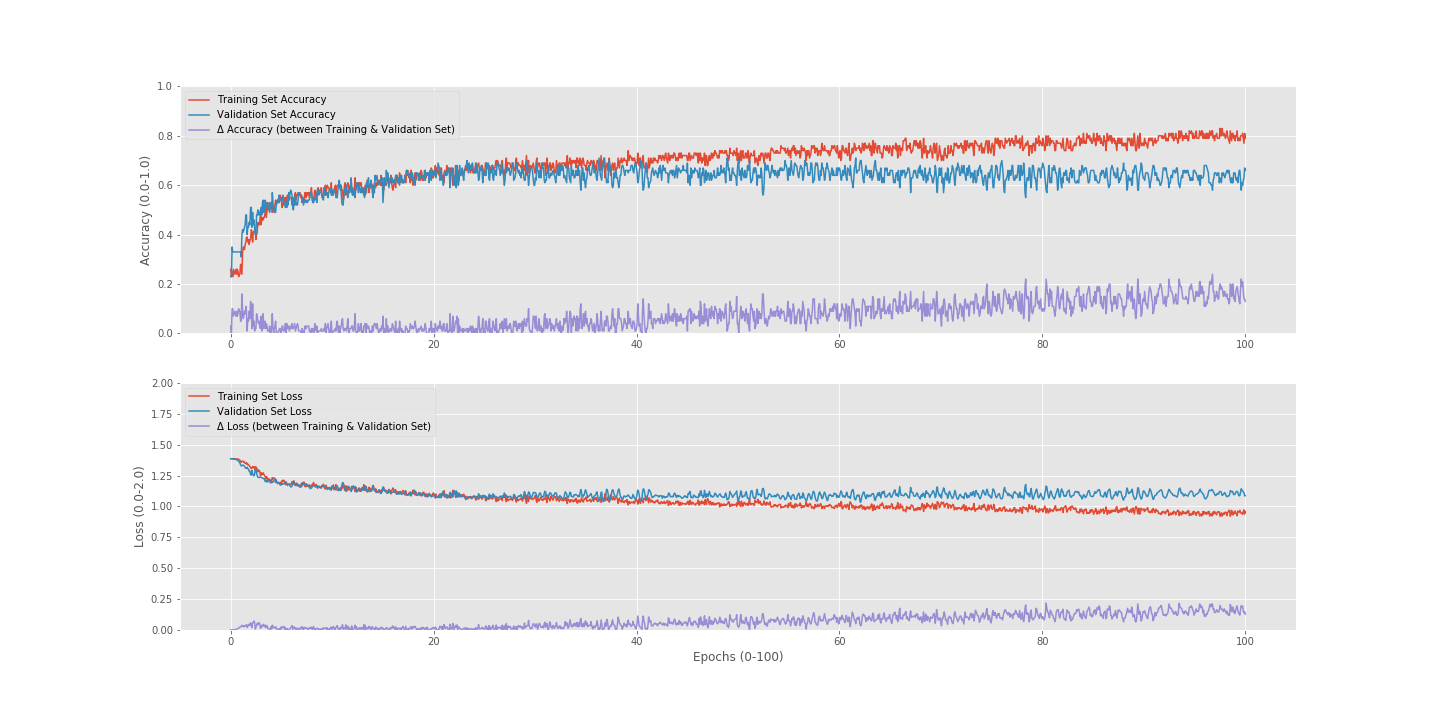
This is what my currect loss/accuracy looks like (the model seems to overfit after 60 epochs and the valdiation accurcy seems hover over 60%):
My current concern is that my data is too random. How can I understand if my data is learnable?
Can I also ask different questions on this thread, if so, what reasons could cause my model to be capable of only learning to a top accuracy of 60-70%? (that is kinda of vague, but I am unsure as to what information would help in this situation and what wound’t)
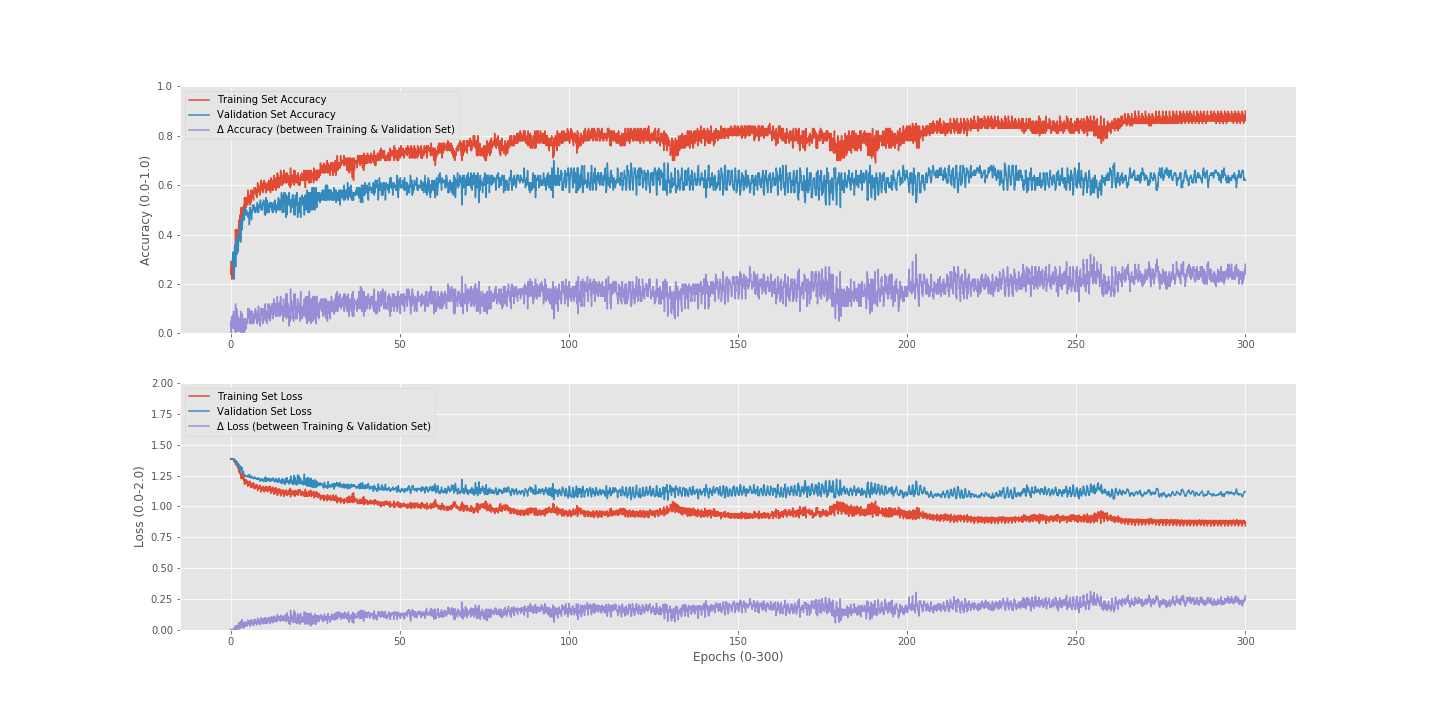
Including more data in one sample of data turned out to me a lot more accurate (made the length of the 1D array larger). Guessing because there weren’t constant features in the data samples previously used. Now the problem I have is inconstancy with my balanced data set. The following are the same models, trained with the same raw dataset, but reprocessed a second time.