I am new in training models, and currently I am trying to train a model using autocast (mixed-precision). I have tried looking at other forums about this error, only 1 solution and it didn’t really help. Any ideas will be accepted. Thank you.
Terminal output :
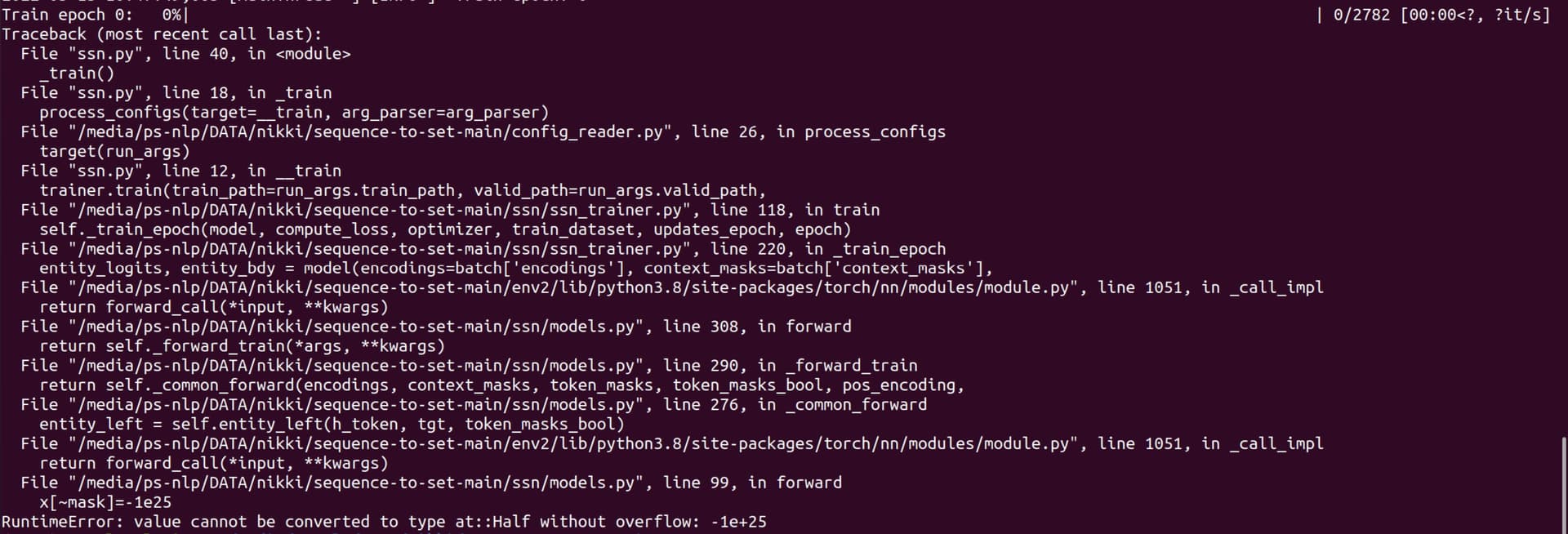
Code with error :
def forward(self, bert, query, mask):
bert_embed = bert.unsqueeze(1).expand(-1, query.size(1), -1, -1)
query_embed = query.unsqueeze(2).expand(-1, -1, bert.size(-2), -1)
fuse = torch.cat([bert_embed, query_embed], dim=-1)
x = self.W(fuse)
x = self.v(torch.tanh(x)).squeeze(-1)
mask = mask.unsqueeze(1).expand(-1, x.size(1), -1)
x[~mask]=-1e+25 if attn_logits.dtype == torch.float32 else -1e+4
x = x.softmax(dim=-1)
return x
Used autocast/autograd/mixed precision in this code :
with autocast():
# forward step
entity_logits, entity_bdy = model(encodings=batch['encodings'], context_masks=batch['context_masks'],
token_masks_bool=batch['token_masks_bool'], token_masks=batch['token_masks'],
pos_encoding = batch['pos_encoding'], wordvec_encoding = batch['wordvec_encoding'],
char_encoding = batch['char_encoding'], token_masks_char = batch['token_masks_char'], char_count = batch['char_count'])
# compute loss and optimize parameters
batch_loss = compute_loss.compute(entity_logits=entity_logits, entity_bdy=entity_bdy, entity_types=batch['gold_entity_types'], entity_spans_token=batch['gold_entity_spans_token'], entity_masks=batch['gold_entity_masks'])
# logging
iteration += 1
global_iteration = epoch * updates_epoch + iteration
epoch_loss += batch_loss / self.args.train_batch_size
if global_iteration % self.args.train_log_iter == 0:
self._log_train(optimizer, batch_loss, epoch, iteration, global_iteration, dataset.label)