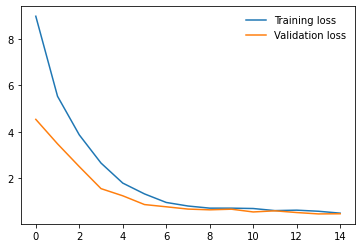
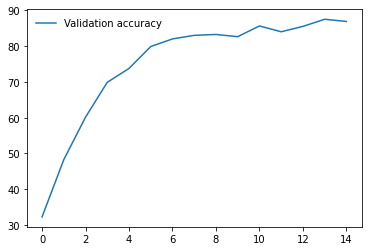
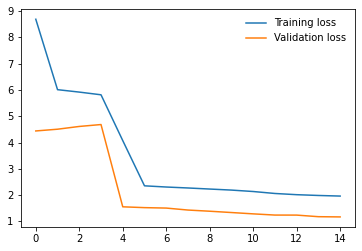
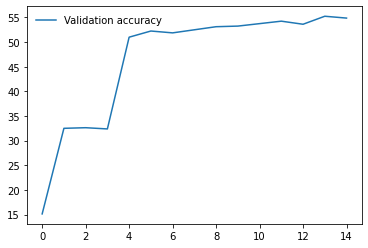
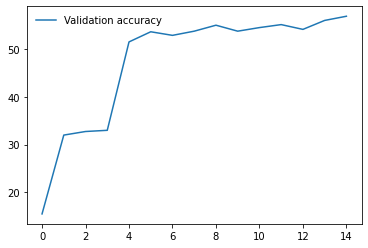
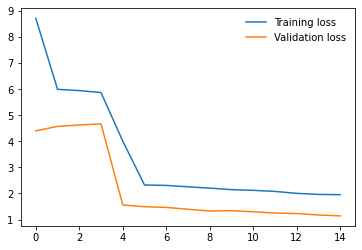
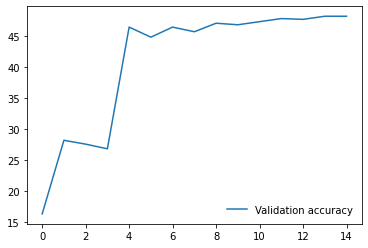
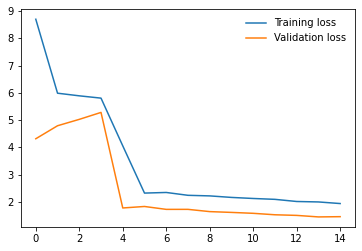
I am working on an image classification problem on a Custom Dataset consisting of 1888 training images and 800 validation images(8 classes). I have tried applying transfer learning using various models from the torchvision.models library. For each model, I am using pre-trained weights and am only training the final Linear layer which performs classification. I have the following results so far on my validation set(using batch size 32 and using SGD with momentum as the optimizer with lr 0.001)
1. Alexnet - 93
2. VGG16 - 93
3. VGG16_bn - 57
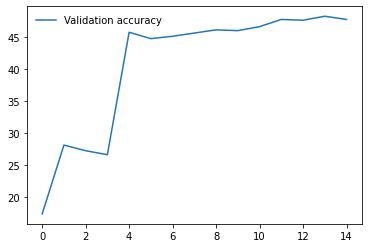
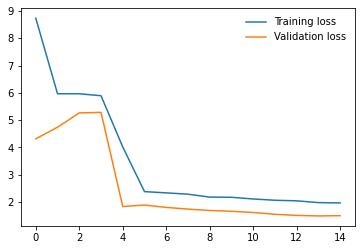
4. Resnet50 - 26
5. VGG19 - 91
6. VGG19_bn - 59
I have repeated the experiments with both model.train() and model.eval() but the results do not seem to change much. So, from the results, I am guessing that the models having BatchNorm layers are performing very poorly compared to other models that don’t have them. Any ideas why this might be happening? Any help would be appreciated. Thanks!
I have looked at this post on the forums about a possible solution which involves increasing the momentum value in the BatchNorm constructor.
How exactly am I supposed to make this change? Do I have to manually change the batchnorm.py code or is there any better way to make this happen?