I’m trying to implement both learning rate warmup and a learning rate schedule within my training loop.
I’m currently using this for learning rate warmup, specifically the LinearWarmup(). So this simply ramps up from 0 to max_lr over a given number of steps.
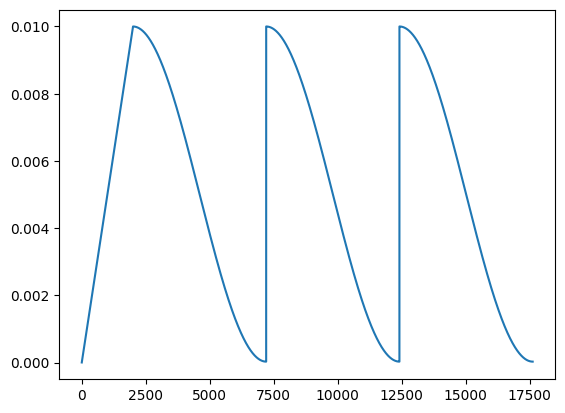
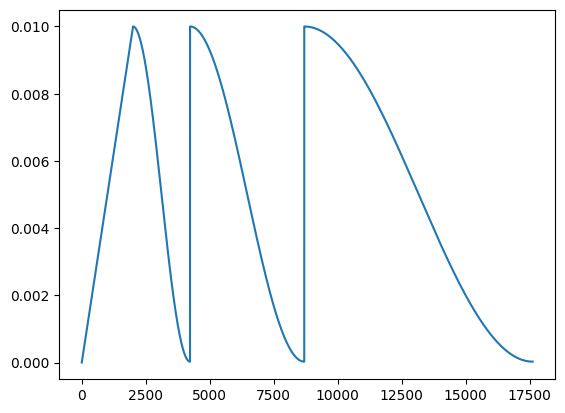
I’m also wanting to use CosineAnnealingWarmRestarts(optimizer, T_0, T_mult) as my lr scheduler.
The challenge is that I’m wanting to use a rather long warm up period, without using an initially high value of T_0. Is there a way I can the LR scheduler to become active over after X number of steps have passed? A simplified version of my code is below. It may also be beneficial to have the LR constant for a number of steps before the scheduled decay begins.
If my initial value of T_0 is not high enough, the LR value during the warm up period follows the pattern of the LR schedule. I’m not sure if this is something that is desirable?
import torch
import pytorch_warmup as warmup
optimizer = torch.optim.AdamW(params, lr=lr)
num_steps = len(dataloader) * num_epochs
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2)
warmup_scheduler = warmup.LinearWarmup(optimizer, warmup_period=1000)
iters = len(dataloader)
for epoch in range(1,num_epochs+1):
for idx, batch in enumerate(dataloader):
optimizer.zero_grad()
loss = ...
loss.backward()
optimizer.step()
with warmup_scheduler.dampening():
lr_scheduler.step(epoch + idx / iters)