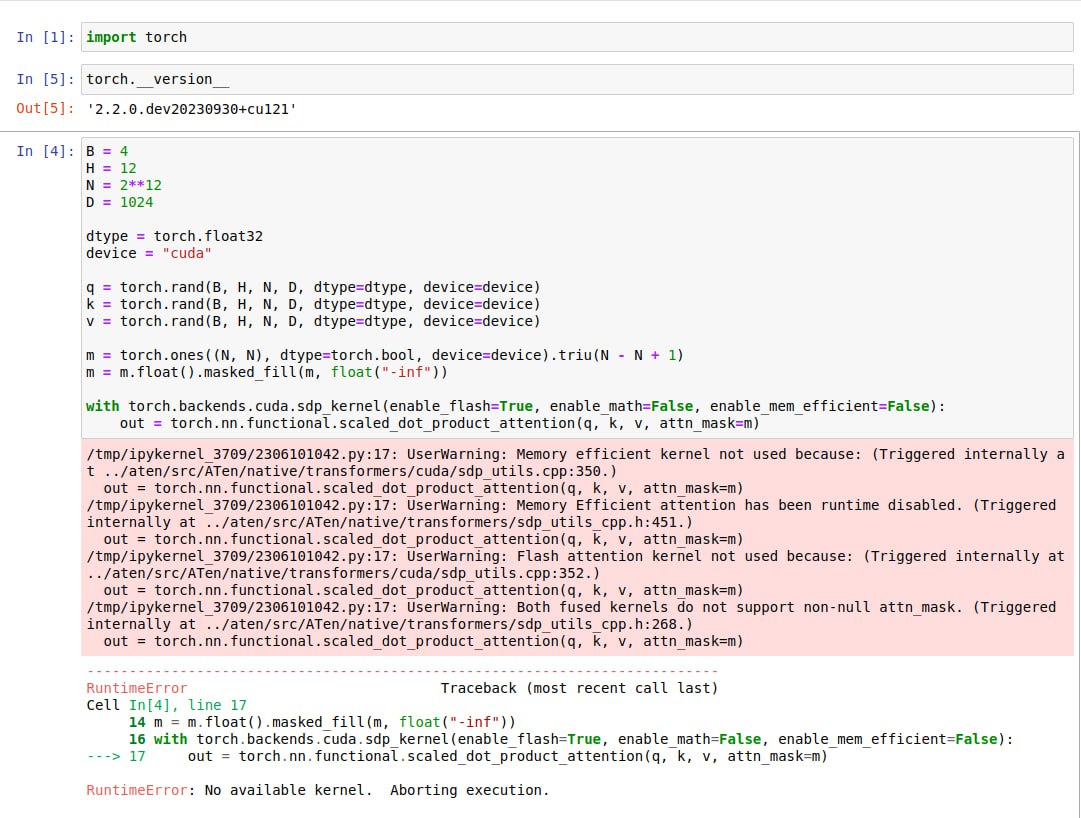
Hello,
I’m trying to run the ‘FlashAttention’ variant of the F.scaled_dot_product_attention by the code below:
import torch
B = 4
H = 12
N = 2**12
D = 1024
dtype = torch.float32
device = "cuda"
q = torch.rand(B, H, N, D, dtype=dtype, device=device)
k = torch.rand(B, H, N, D, dtype=dtype, device=device)
v = torch.rand(B, H, N, D, dtype=dtype, device=device)
m = torch.ones((N, N), dtype=torch.bool, device=device).triu(N - N + 1)
m = m.float().masked_fill(m, float("-inf"))
with torch.backends.cuda.sdp_kernel(enable_flash=False, enable_math=False, enable_mem_efficient=True):
out = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=m)
I tried to run this code in two machines:
- Google Colab with Tesla T4
- my own PC with 4080
I found this topic: Using F.scaled_dot_product_attention gives the error RuntimeError: No available kernel. Aborting execution and tried to install nightly version by the command pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu121 from the comments. Either I used wrong command to install right version or there is new problem for using FlashAttention from pytorch
I will be grateful for your answers!