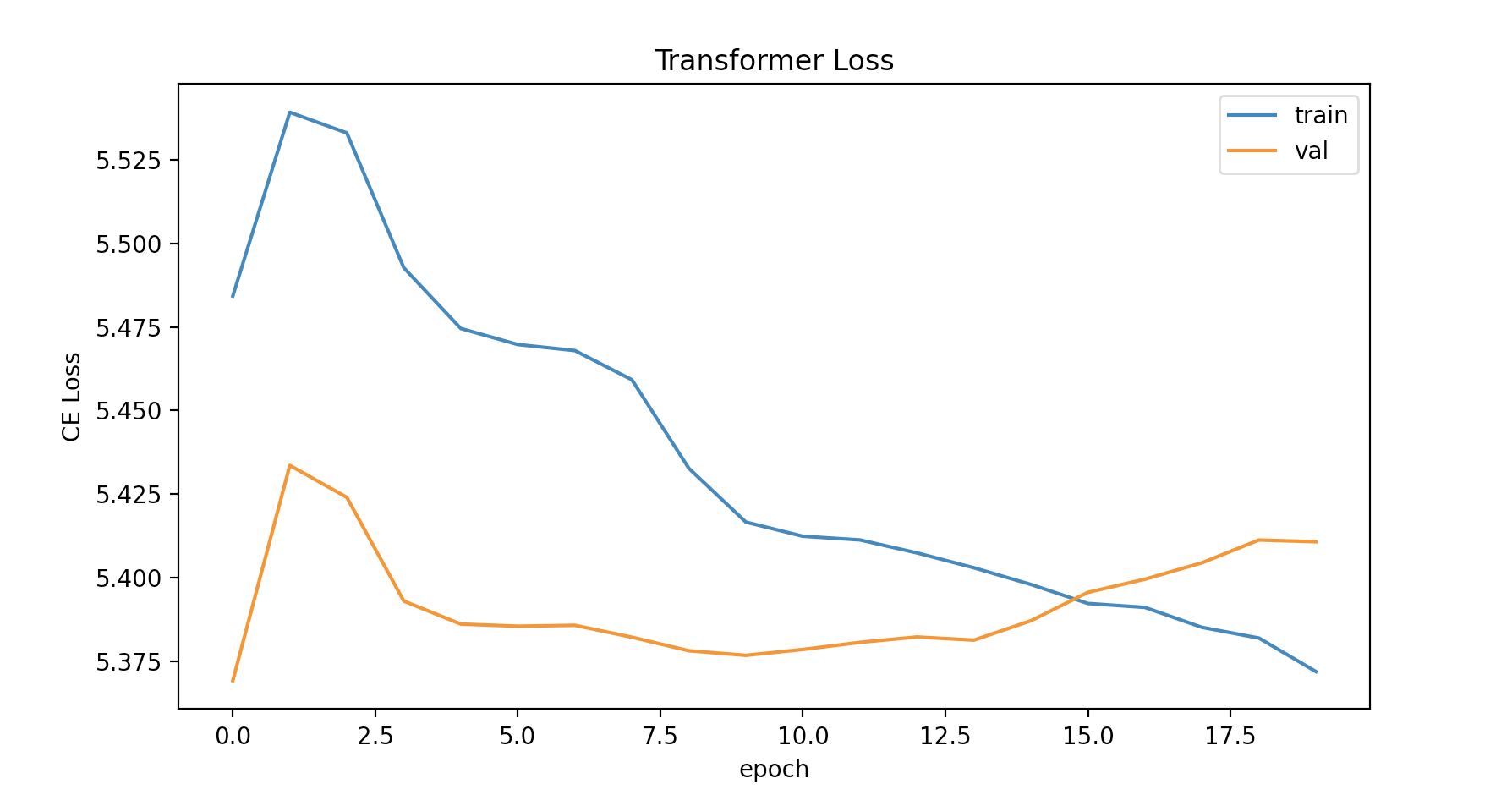
I am doing a machine translation task with Cross Entropy loss, where each sentence in the target is padded with ‘0’ values to the maximum length sentence of the dataset. I first trained my network without using ignore_index (1st picture), then set ignore_index=0, and the loss increases in magnitude (2nd picture) to around 5.

Here is my code and tensor dimensions:
# init mask
mask = torch.tril(torch.ones((MAX_LENGTH, MAX_LENGTH))).to(DEVICE)
# optimization loop
best_loss = 1e5
best_epoch = 0
optimizer=torch.optim.Adam(params=model.parameters(),lr=1e-3)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=0)
train_losses = []
val_losses = []
for epoch in range(1,EPOCHS+1):
# train loop
for i, (src,trg) in enumerate(train_data):
# place tensors to device
src = torch.Tensor(src).to(DEVICE).long()
trg = torch.Tensor(trg).to(DEVICE).long()
# forward pass
out = model(src,trg, mask)
print('out: ', out.size())
print('trg: ', trg.size())
print('out reshaped: ', out.view(-1, tgt_vocab).size())
print('trg reshaped: ', trg.view(-1).size())
# compute loss
train_loss = loss_fn(out.view(-1,tgt_vocab), trg.view(-1))
# backprop
optimizer.zero_grad()
train_loss.backward()
# update weights
optimizer.step()
out: torch.Size([64, 60, 3194])
trg: torch.Size([64, 60])
out reshaped: torch.Size([3840, 3194])
trg reshaped: torch.Size([3840])