this is my model
class Siamese(nn.Module):
def __init__(self):
super(Siamese, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 64, 10), # 64@96*96
nn.ReLU(inplace=True),
nn.MaxPool2d(2), # 64@48*48
nn.Conv2d(64, 128, 7),
nn.ReLU(), # 128@42*42
nn.MaxPool2d(2), # 128@21*21
nn.Conv2d(128, 128, 4),
nn.ReLU(), # 128@18*18
nn.MaxPool2d(2), # 128@9*9
nn.Conv2d(128, 256, 4),
nn.ReLU(), # 256@6*6
)
self.liner = nn.Sequential(nn.Linear(9216, 4096), nn.Sigmoid())
self.out = nn.Linear(4096, 1)
def forward_one(self, x):
x = self.conv(x)
x = x.view(x.size()[0], -1)
x = self.liner(x)
return x
def forward(self, x1, x2):
out1 = self.forward_one(x1)
out2 = self.forward_one(x2)
dis = torch.abs(out1 - out2)
out = self.out(dis)
return out
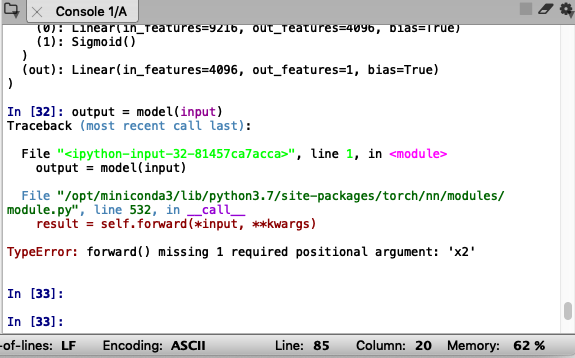
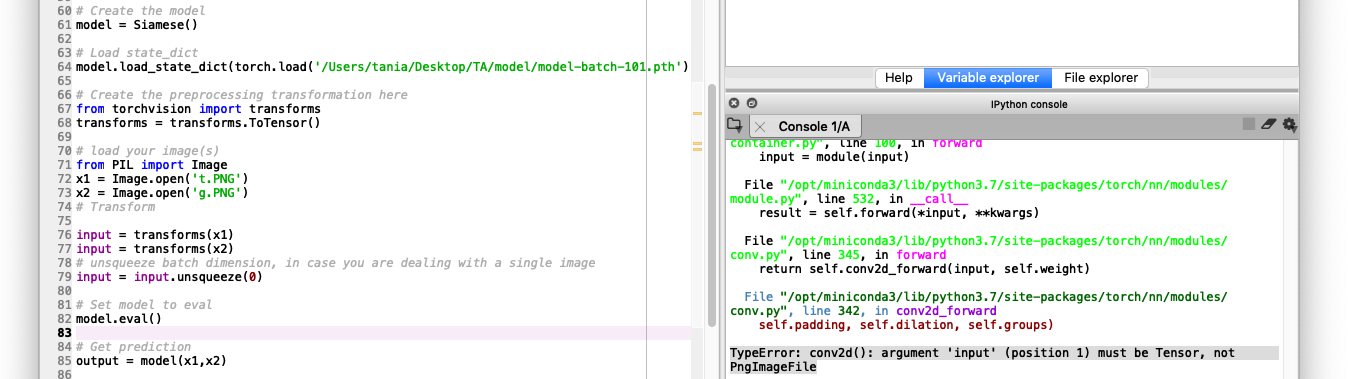
when I want to test the resulting model, an error appears stating the requested input is 4 but entering 3 dimensional input.
I think there is a problem in the image that I will test
from PIL import Image
x1 = Image.open('t.PNG')
x2 = Image.open('g.PNG')
the error is said that I put an image with a size of 105x105, even though the test image that I input is not 105.
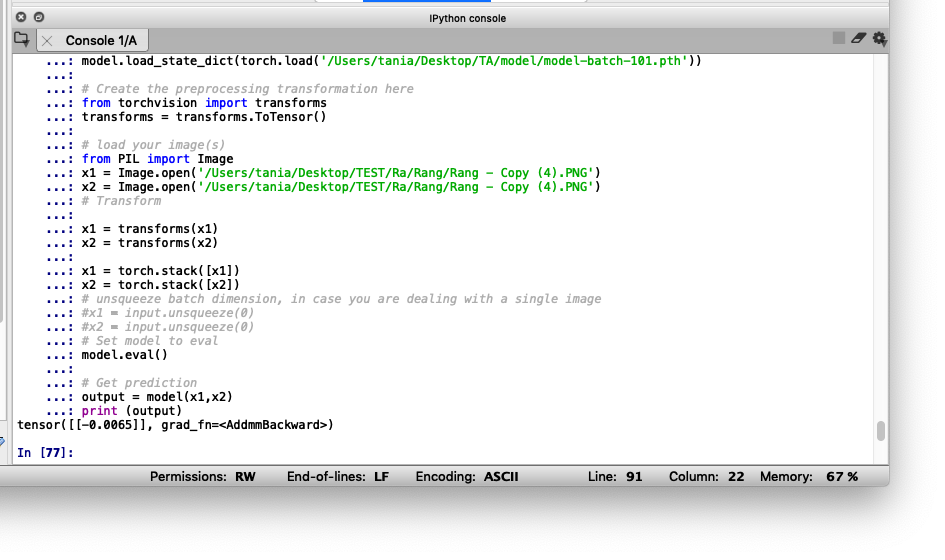
but i was wrong, maybe the error tell me about my data that i use to training.
An image with a size of 105x105 is an image that I used for the train process to produce a siamese neural network model.
I follow this post in the siamese process (https://github.com/Ameyapores/one_shot_learning.git)
please help me,