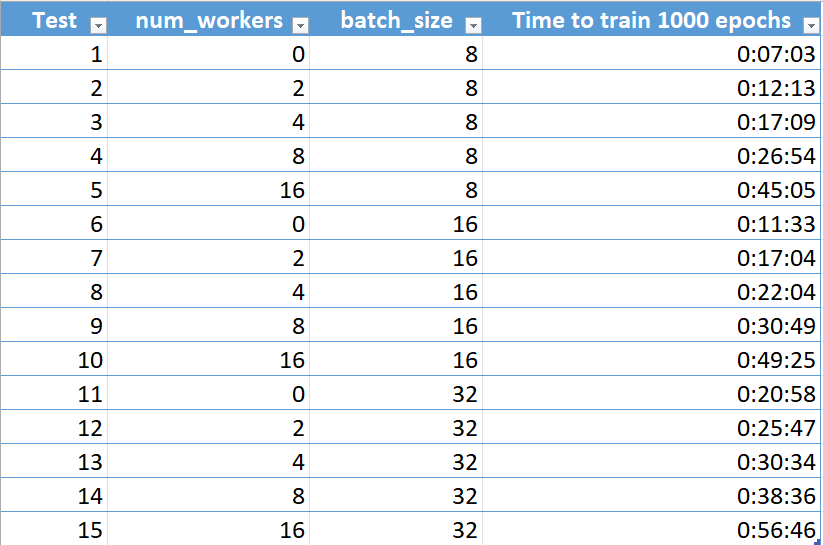
My code works well when I am just using single GPU to do the training. I would like to speed up the training by utlilizing 8 GPUs by using DistributedDataParallel. However, I noticed that using more GPUs does not speed up the training for me at all. Instead, using more GPUs makes the training slower.
I also tried to modify the batch size and I noticed that batch size = 8 trains the model fastest. Increasing the batch size will makes the training significantly slower.
I tried to measure the time for each epoch and found the training time is significantly longer every 4 epochs.
EP0_elapsed_time: 3.3021082878112793 sec
EP1_elapsed_time: 0.8542821407318115 sec
EP2_elapsed_time: 0.7720010280609131 sec
EP3_elapsed_time: 7.11009407043457 sec
EP4_elapsed_time: 0.7670211791992188 sec
EP5_elapsed_time: 0.7623276710510254 sec
EP6_elapsed_time: 0.7690849304199219 sec
EP7_elapsed_time: 7.0614259243011475 sec
EP8_elapsed_time: 0.7806422710418701 sec
EP9_elapsed_time: 0.7751979827880859 sec
EP10_elapsed_time: 0.7685496807098389 sec
EP11_elapsed_time: 7.09734845161438 sec
EP12_elapsed_time: 0.7923364639282227 sec
EP13_elapsed_time: 0.7789566516876221 sec
EP14_elapsed_time: 0.7974681854248047 sec
EP15_elapsed_time: 7.120237350463867 sec
I notice a similar problem in the forum and it has not been solved.
No speedup doing multi GPU training with DistributedDataParallel vs. single GPU
How can I solve this issue?
main()
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking/index within the nodes')
parser.add_argument('--epochs', default=400, type=int, metavar='N', help='number of total epochs to run')
parser.add_argument('--model_dir', default='stylegan2ada_002', type=str, help='model dir name')
parser.add_argument('--train_img_dir_path', default='./GAN/clean_2', type=str, help='training images dir path')
parser.add_argument('--img_size', default=64, type=int, help='target image size')
parser.add_argument('--batch_size', default=32, type=int, help='batch size')
parser.add_argument('--g_latent_dim', default=512, type=int, help='dim of generator noise z and w')
parser.add_argument('--mn_num_layers', default=8, type=int, help='number of layers in the mapping network (8 according to paper)')
parser.add_argument('--g_lr', default=1e-3, type=float, help='generator learning rate')
parser.add_argument('--d_lr', default=1e-3, type=float, help='discriminator learning rate')
parser.add_argument('--mn_lr', default=1e-5, type=float, help='mapping network learning rate')
parser.add_argument('--adam_betas', default=(0.0, 0.99), type=tuple, help='betas of adam optimizers')
parser.add_argument('--gradient_accumulate_steps', default=1, type=int, help='gradient accumulate steps')
parser.add_argument('--lazy_gradient_penalty_interval', default=4, type=int, help='lazy gradient penalty interval')
parser.add_argument('--lazy_path_penalty_after', default=5000, type=int, help='the point that starts to apply lazy path penalty')
parser.add_argument('--lazy_path_penalty_interval', default=32, type=int, help='lazy path penalty interval')
parser.add_argument('--gradient_penalty_coefficient', default=10., type=float, help='gradient penalty coefficient')
parser.add_argument('--style_mixing_prob', default=0.9, type=float, help='style mixing prob')
parser.add_argument('--generate_img_interval', default=100, type=int, help='generate images every x epochs')
parser.add_argument('--generate_img_after_percent', default=0.4, type=float, help='generate images after y% of the total epochs')
args = parser.parse_args()
args.world_size = args.gpus * args.nodes
args.distributed = True
args.dist_backend = 'nccl'
args.dist_url = 'env://'
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '7788'
mp.spawn(train, nprocs=args.gpus, args=(args,))
train()
def train(gpu, args):
rank = args.nr * args.gpus + gpu
torch.cuda.set_device(gpu)
dist.init_process_group(
backend=args.dist_backend,
init_method=args.dist_url,
world_size=args.world_size,
rank=rank,
)
dist.barrier()
# Measure time
start_init = time.time()
# Make dirs
### Create model dir if not existed
model_dir_path = f'./{args.model_dir}'
if not (os.path.exists(model_dir_path)):
try:
os.makedirs(model_dir_path)
except:
pass
### Create 'images' dir if not existed
img_dir_path = f'./{args.model_dir}/images'
if not (os.path.exists(img_dir_path)):
try:
os.makedirs(img_dir_path)
except:
pass
### Create 'checkpoints' dir if not existed
ckpt_dir_path = f'./{args.model_dir}/checkpoints'
if not (os.path.exists(ckpt_dir_path)):
try:
os.makedirs(ckpt_dir_path)
except:
pass
# Dataset and Dataloader
### Create the dataset
dataset = ImageDataset(path=args.train_img_dir_path, image_size=args.img_size)
sampler = torch.utils.data.distributed.DistributedSampler(
dataset,
num_replicas=args.world_size,
rank=rank,
)
### Create the dataloader
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=args.batch_size,
num_workers=0,
shuffle=False,
drop_last=True,
pin_memory=True,
sampler=sampler,
)
# Initialization
### Setup gpu device
device = torch.device('cuda', rank)
### Get log2 of the target image size
log_resolution = log2(args.img_size)
### Create discriminator
discriminator = Discriminator(log_resolution)
### Put the discriminator to the device
discriminator.to(device)
### Apply DDP
discriminator = nn.parallel.DistributedDataParallel(discriminator, device_ids=[gpu])
### Create discriminator loss
discriminator_loss = DiscriminatorLoss().to(device)
### Create discriminator optimizer
discriminator_optimizer = torch.optim.Adam(
discriminator.parameters(),
lr = args.d_lr,
betas = args.adam_betas,
)
### Create gradient penalty (gp) loss
gradient_penalty = GradientPenalty()
### Create generator
generator = Generator(device, log_resolution, args.g_latent_dim, args.style_mixing_prob)
### Put the generator to the device
generator.to(device)
### Apply DDP
generator = nn.parallel.DistributedDataParallel(generator, device_ids=[gpu])
### Create generator loss
generator_loss = GeneratorLoss().to(device)
### Create generator optimizer
generator_optimizer = torch.optim.Adam(
generator.parameters(),
lr = args.g_lr,
betas = args.adam_betas,
)
### Create path length penalty (PLP) loss
path_length_penalty = PathLengthPenalty(0.99).to(device)
### Create mapping network
mapping_network = MappingNetwork(args.g_latent_dim, args.mn_num_layers)
### Put the mapping network to the device
mapping_network.to(device)
### Apply DDP
mapping_network = nn.parallel.DistributedDataParallel(mapping_network, device_ids=[gpu])
### Create mapping network optimizer
mapping_network_optimizer = torch.optim.Adam(
mapping_network.parameters(),
lr = args.mn_lr,
betas = args.adam_betas,
)
generate_img_after = int(args.epochs * args.generate_img_after_percent)
# Measure time
torch.cuda.synchronize()
end_init = time.time()
init_time = end_init - start_init
print(f'Init_time: {init_time} sec')
# Training steps and losses tracking
disc_loss_y = []
gen_loss_y = []
# Measure time
times = []
for i in range(args.epochs):
start_epoch = time.time()
disc_loss, gen_loss = step(
i,
device,
args.batch_size,
dataloader,
args.gradient_accumulate_steps,
args.style_mixing_prob,
discriminator,
discriminator_loss,
discriminator_optimizer,
gradient_penalty,
args.gradient_penalty_coefficient,
args.lazy_gradient_penalty_interval,
generator,
generator_loss,
generator_optimizer,
path_length_penalty,
args.g_latent_dim,
args.lazy_path_penalty_after,
args.lazy_path_penalty_interval,
mapping_network,
mapping_network_optimizer,
args.model_dir,
args.generate_img_interval,
generate_img_after,
)
# Measure time
torch.cuda.synchronize()
end_epoch = time.time()
elapsed = end_epoch - start_epoch
times.append(elapsed)
print(f'EP{i}_elapsed_time: {elapsed} sec')
### Append losses of each step into the lists
disc_loss_y.append(disc_loss)
gen_loss_y.append(gen_loss)
# Measure time
avg_time = sum(times)/args.epochs
print(f'avg_time: {avg_time} sec')
### Plot the losses
epoch_x = np.linspace(1, args.epochs, args.epochs).astype(int)
plt.plot(epoch_x, disc_loss_y, label='disc_loss')
plt.plot(epoch_x, gen_loss_y, label='gen_loss')
plt.legend()
plt.savefig(f'{img_dir_path}/loss.png')