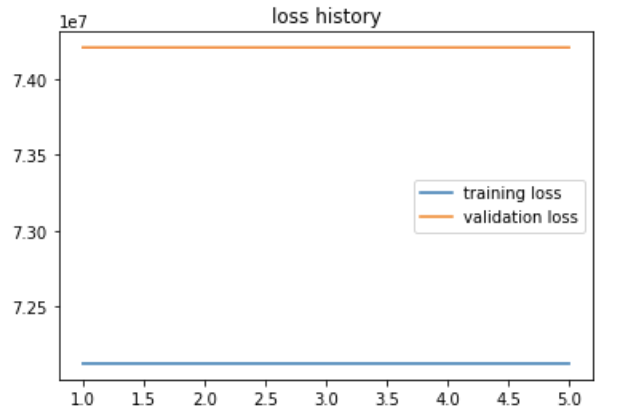
I’m now trying to use multiple models and optimizers in training.
During the training, it seems like the loss is not decreasing.
Can anyone know what the problem is?
The code is below
I have multiple models and optimizers, and in the for c in range(classnum):
loop, I am trying to compute the loss from each model and optimizing the model with optimizers corresponds to the model.
Note that each optimizer is different alghorithm.
models = list[mode1, model2,...., model10]
optimizers = list[optimizer1, optimizer2,...., optimizer10]
for model in models:
model.train()
for step, inputs in enumerate(tqdm(train_loader)):
inputs = inputs.to(device)
for c in range(classnum):
optimizers[c].zero_grad()
:
:
:
outputs, mean, logvar = models[c].forward(each_input)
kld, recon = loss_function(outputs, each_input, mean, logvar, each_weights)
loss = kld + recon
loss.backward()
optimizers[c].step()
running_loss += loss.item()
So it is training just very very slowly? Have you tried different learning rate? What about only 2 models?
I don’t know what your loss is, but is it properly averaged over the samples?
I’m using Adam as an optimizer and tried several learning rate.
But nothing actually changes. And haven’t tried training with 2 models yet.
The loss function is torch.nn.BCELoss and the reason that loss is large is that because reduction is sum.
The original data’s shapes are (batch size, C, H, W) = (32, 10, 100, 100) and during the training, I’m training each channel with an independent model and optimizer. Which means the shape of input data to model is (32, 1, 100, 100).
And also original data is the output of the segmentation model, so each channel is the probability.