Hey guys,
i m looking for help to correctly implement roc curves for my leaving one out code. Something doesn’t work well. My roc curve looks like:
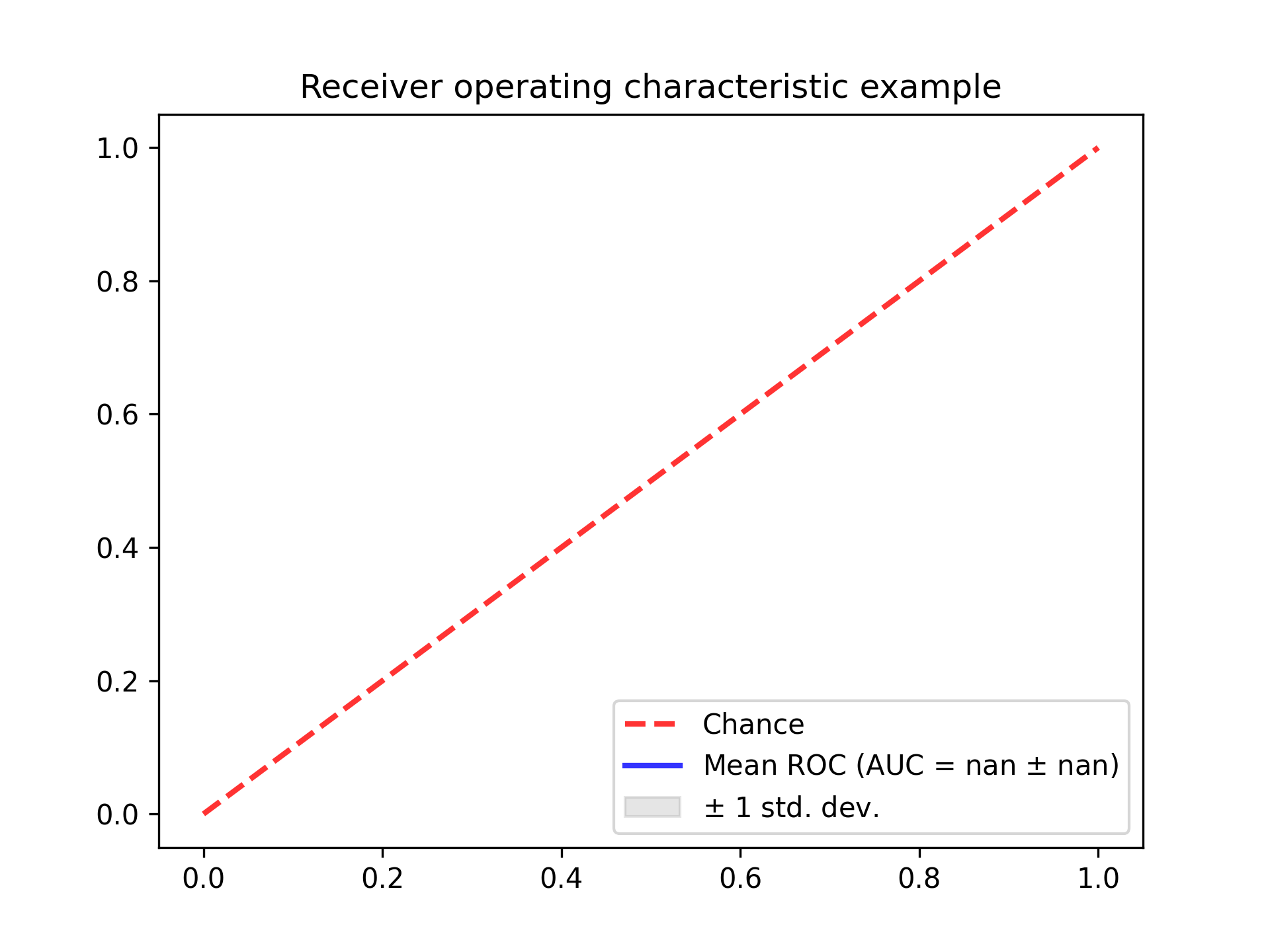
I was looking in the internet for some instructions/examples how to implement the roc curves for leaving one out but what i have founded doesn’t match to my requirements.
In my code i dont use any pipeline and so i dont can use this lines of code:
classifier.fit(X[train], y[train])
(classifier, X[test], y[test], name='ROC fold {}'.format(i), alpha=0.3, lw=1, ax=ax)
i’m also not really sure what’s about mean_fpr = numpy.linspace)(0, 1, 100)
Here is my full code:
import train
import model
import data_preparation
import plot_graph
import matplotlib.pyplot as plt
import yaml
import numpy as np
from sklearn.metrics import confusion_matrix
#PyTorch DataLoader
import torch
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler, dataloader
from sklearn import svm, datasets
from sklearn.metrics import auc
from sklearn.metrics import plot_roc_curve
# Function to print ROC and AUC
from sklearn.metrics import accuracy_score, roc_curve, auc
# loading config params
project_root = "/mnt/XX/user/XX/XX"
with open(project_root+"/config.yml") as f:
params = yaml.load(f, Loader=yaml.FullLoader)
#DATA LOAD
import numpy as np
from sklearn.model_selection import LeaveOneOut
import pandas as pd
tprs = []
aucs = []
mean_fpr = np.linspace(0, 1, 100)
fig, ax = plt.subplots()
#for test purpose to avoid full loop of the whole data set
i = 0
# Load data and set labels
data_z = pd.read_csv('csv/z.csv', error_bad_lines=False, encoding= 'unicode_escape')
data_z['label'] = 0
data_a = pd.read_csv('csv/a.csv', error_bad_lines=False, encoding= 'unicode_escape')
data_a['label'] = 1
# Concatenate data
data = pd.concat([data_z, data_a], axis=0).reset_index(drop=True)
X = data.le.values
y = data.label.values
loo = LeaveOneOut()
loo.get_n_splits(X)
LeaveOneOut()
for train_index, test_index in loo.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
train_inputs, train_masks = data_preparation.preprocessing_for_bert(X_train)
val_inputs, val_masks = data_preparation.preprocessing_for_bert(X_test)
#------------------------------- --------------------------------
#------------------------------- DATALOADER --------------------------------
#------------------------------- --------------------------------
# Convert other data types to torch.Tensor
train_labels = torch.tensor(y_train)
val_labels = torch.tensor(y_test)
# For fine-tuning BERT, the authors recommend a batch size of 16 or 32.
batch_size = params["training"]["batch_size"]
# Create the DataLoader for our training set
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
# Create the DataLoader for our validation set
val_data = TensorDataset(val_inputs, val_masks, val_labels)
val_sampler = SequentialSampler(val_data)
val_dataloader = DataLoader(val_data, sampler=val_sampler, batch_size=batch_size)
#Training Start
train.set_seed(params["training"]["seed"]) # Set seed for reproducibility
model.bert_classifier, train.optimizer, train.scheduler = train.initialize_model(epochs=params["training"]["epochs"])
train.train(model.bert_classifier, train_dataloader, val_dataloader, epochs=params["training"]["epochs"], evaluation=False)
probs = train.bert_predict(model.bert_classifier, val_dataloader)
i = i +1
print(i)
if i == 2:
break;
preds = probs[:, 1]
fpr, tpr, threshold = roc_curve(y_test, preds)
roc_auc = auc(fpr, tpr)
print(f'AUC: {roc_auc:.4f}')
# Get accuracy over the test set
y_pred = np.where(preds >= 0.5, 1, 0)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy*100:.2f}%')
interp_tpr = np.interp(mean_fpr, fpr, tpr)
interp_tpr[0] = 0.0
tprs.append(interp_tpr)
aucs.append(roc_auc)
ax.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r',
label='Chance', alpha=.8)
mean_tpr = np.mean(tprs, axis=0)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
std_auc = np.std(aucs)
ax.plot(mean_fpr, mean_tpr, color='b',
label=r'Mean ROC (AUC = %0.2f $\pm$ %0.2f)' % (mean_auc, std_auc),
lw=2, alpha=.8)
std_tpr = np.std(tprs, axis=0)
tprs_upper = np.minimum(mean_tpr + std_tpr, 1)
tprs_lower = np.maximum(mean_tpr - std_tpr, 0)
ax.fill_between(mean_fpr, tprs_lower, tprs_upper, color='grey', alpha=.2,
label=r'$\pm$ 1 std. dev.')
ax.set(xlim=[-0.05, 1.05], ylim=[-0.05, 1.05],
title="Receiver operating characteristic example")
ax.legend(loc="lower right")
plt.savefig('graphen/ROC AUC.png', dpi=300)
plt.close()
I m not an expert and it would be really lovely if you some code help me out with my struggle.
thank you so much!