I have a theoretical doubt regarding the use of a different instance of optimizers for encoder and decoder respectively vs using a single optimizer for the complete autoencoder network.
I initially thought it was the same, but then I conducted an experiment on this and found, the loss of multiple optimizers tends to remain lower comparatively.
Code for the two versions is as follows:
def get_optimizer(config, net):
if config.OPTIMIZER == 'Adam' or config.OPTIMIZER == 'adam':
optimizer = optim.Adam(filter(lambda p: p.requires_grad, net.parameters()), \
lr=config.BASE_LR, betas=(0.9, 0.999),
weight_decay=config.WEIGHT_DECAY)
elif config.OPTIMIZER == 'SGD' or config.OPTIMIZER == 'sgd':
optimizer = optim.SGD(net.parameters(), lr=config.BASE_LR, momentum=config.LEARNING_MOMENTUM, weight_decay=config.WEIGHT_DECAY)
else:
raise NotImplementedError
return optimizer
For Multi Optimizers
def create_optimizers(config, enc, dec):
net_encoder, net_decoder = enc, dec
if config.OPTIMIZER == 'SGD' or config.OPTIMIZER == 'sgd':
optimizer_encoder = optim.SGD(
group_weight(net_encoder),
lr=config.BASE_LR,
momentum=config.LEARNING_MOMENTUM,
weight_decay=config.WEIGHT_DECAY)
optimizer_decoder = optim.SGD(
group_weight(net_decoder),
lr=config.BASE_LR,
momentum=config.LEARNING_MOMENTUM,
weight_decay=config.WEIGHT_DECAY)
elif config.OPTIMIZER == 'Adam' or config.OPTIMIZER == 'adam':
optimizer_encoder = optim.Adam(
group_weight(net_encoder),
lr=config.BASE_LR,
betas=(0.9, 0.999),
weight_decay=config.WEIGHT_DECAY)
optimizer_decoder = optim.Adam(
group_weight(net_decoder),
lr=config.BASE_LR,
betas=(0.9, 0.999),
weight_decay=config.WEIGHT_DECAY)
return (optimizer_encoder, optimizer_decoder)
The Loss curves are as follows
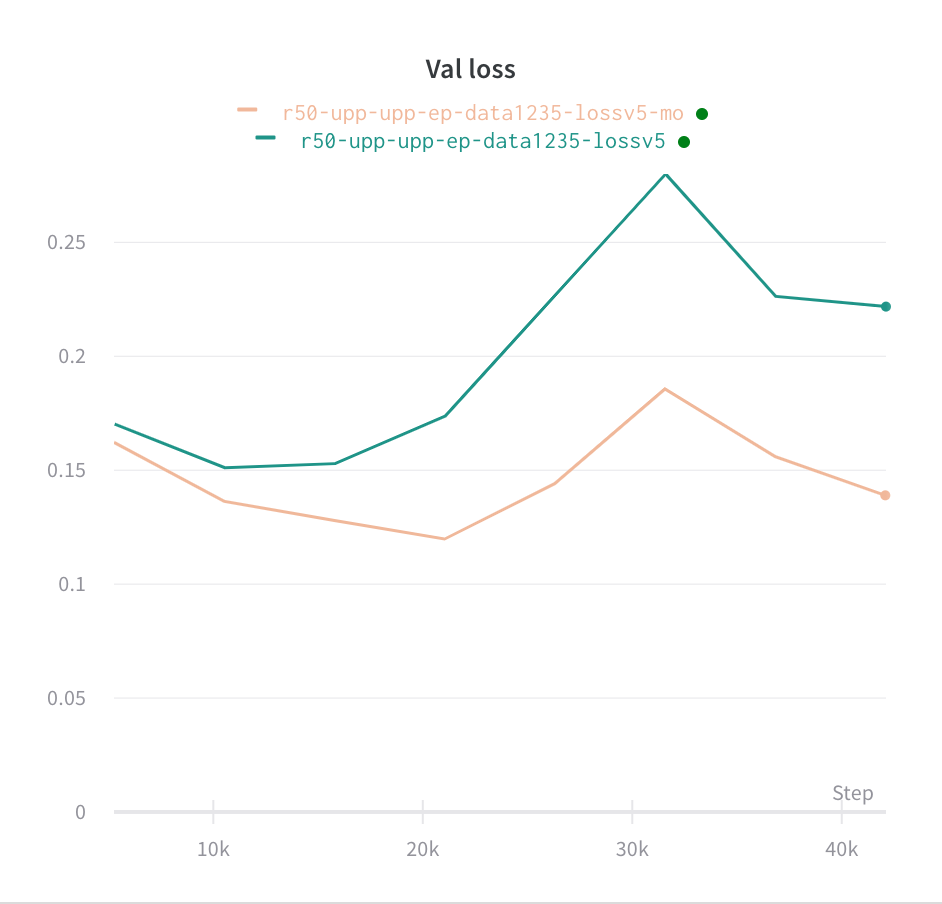
Can somebody explain this or is this just a coincidence.