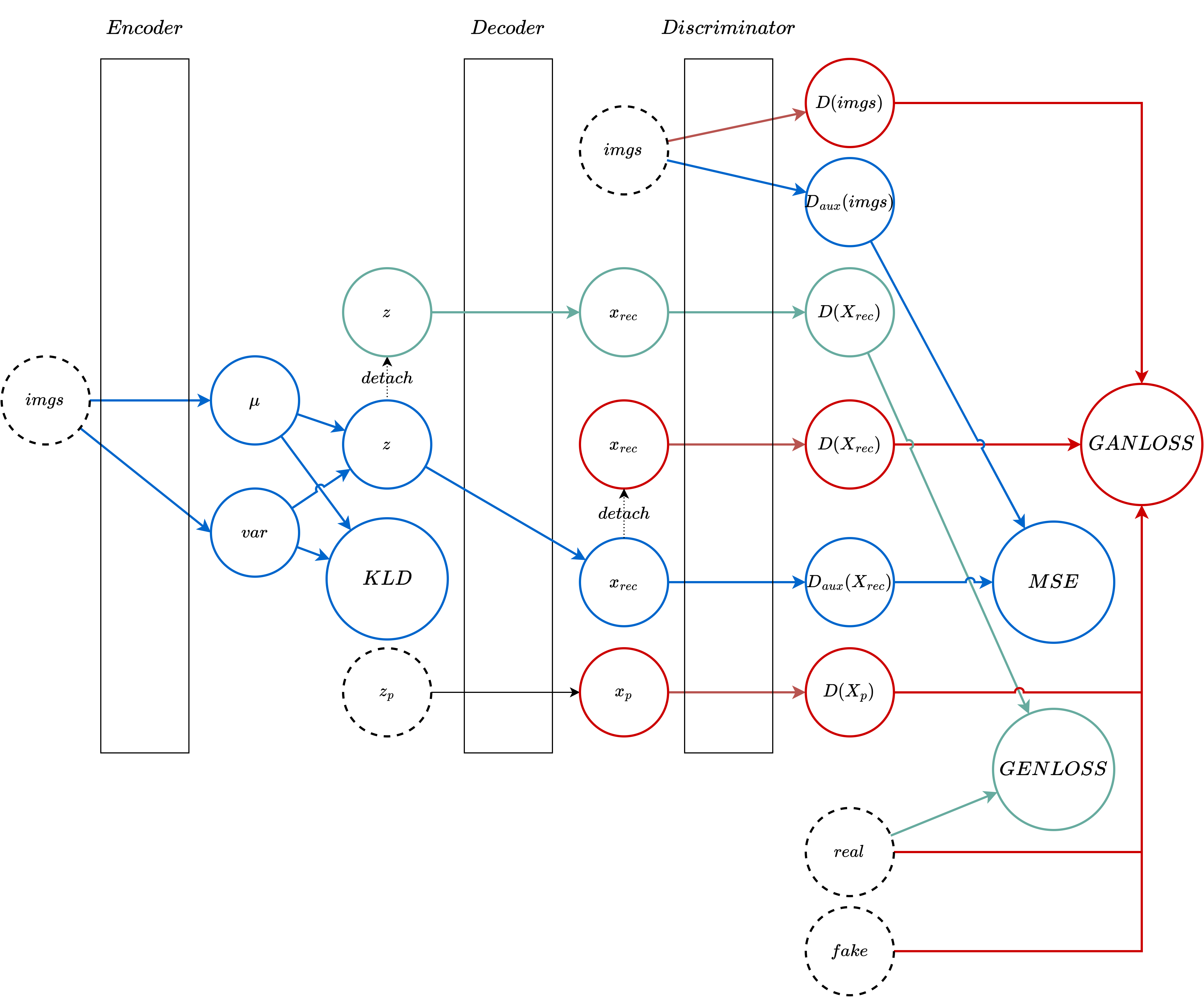
Hello,
I am at a loss when implementing the training part of a VAE+GAN. This is specifically because the full VAE+GAN uses different losses to train different parts of the VAE+GAN. The base paper I am trying to implement is here: https://arxiv.org/pdf/1512.09300. I tried several training procedures:
- using a single backward pass by adding all losses but I am not sure the gradients are propagated correctly as the paper states that the different parts of the network should be trained with different combinations of losses
- using multiple backward passes but with
retain_graph=Truedespite knowing that this is frowned upon except for very specific cases. This also throws errors due to inplace operations (see code below). - alternating between zeroing gradients and backward passes for each network within the full VAE+GAN, but this throws propagation errors as the gradients are already freed by previous passes.
As much as possible, I would like to avoid having to do multiple forward passes. I tried detaching tensors from the computation graphs but to no avail.
Here is an example with an MNIST dataset and the multiple backward passes case.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision import datasets
from torch.utils.data import DataLoader
class Encoder(nn.Module):
def __init__(self, in_channels, z_dim):
super(Encoder, self).__init__()
self.layers = 3
kernel_size = 5
stride = 2
padding = 1
self.conv = []
current_in = in_channels
current_out = 16
for i in range(self.layers):
if i == self.layers - 1:
self.conv.append(
nn.Conv2d(current_in, current_out, kernel_size, stride, padding, bias=False)
)
else:
self.conv.append(
nn.Conv2d(current_in, current_out, kernel_size, stride, padding, bias=False)
)
self.conv.append(nn.BatchNorm2d(current_out))
self.conv.append(nn.LeakyReLU(0.2))
self.conv.append(nn.Dropout(0.3))
current_in = current_out
current_out *= 2
current_out = current_out // 2
self.conv = nn.Sequential(*self.conv)
self.var = nn.Linear(current_out * 2 * 2, z_dim)
self.mu = nn.Linear(current_out * 2 * 2, z_dim)
self.flatten = nn.Flatten()
def forward(self, x):
x = self.conv(x)
# mu = self.mu(x.view)
mu = self.mu(self.flatten(x))
var = self.var(self.flatten(x))
return mu, var
class Decoder(nn.Module):
def __init__(self, z_dim, target_shape):
super(Decoder, self).__init__()
self.base_channels = 256
self.base_feature_maps = 4
self.layers = 3
self.fc = nn.Linear(z_dim, self.base_channels * self.base_feature_maps * self.base_feature_maps)
self.unflatten = nn.Unflatten(
1,
(self.base_channels, self.base_feature_maps, self.base_feature_maps))
self.conv = []
current_in = self.base_channels
kernel_size = 4
stride = 2
padding = 1
for i in range(self.layers):
if i == self.layers - 1:
current_out = 1
self.conv.append(
nn.ConvTranspose2d(current_in, current_out, kernel_size, stride, padding, bias=False),
)
self.conv.append(nn.Upsample(target_shape))
self.conv.append(nn.Sigmoid())
else:
current_out = max(current_in // 2, 1)
self.conv.append(
nn.ConvTranspose2d(current_in, current_out, kernel_size, stride, padding, bias=False),
)
self.conv.append(nn.BatchNorm2d(current_out))
self.conv.append(nn.LeakyReLU(0.2))
current_in = current_out
self.conv = nn.Sequential(*self.conv)
def forward(self, z):
x = self.fc(z)
x = self.unflatten(x)
x = self.conv(x)
return x
class Discriminator(nn.Module):
def __init__(self, in_channels):
super(Discriminator, self).__init__()
self.layers = 3
kernel_size = 5
stride = 2
padding = 1
self.conv = []
current_in = in_channels
current_out = 16
for i in range(self.layers):
if i == self.layers - 1:
self.conv.append(
nn.Conv2d(current_in, current_out, kernel_size, stride, padding, bias=False)
)
else:
self.conv.append(
nn.Conv2d(current_in, current_out, kernel_size, stride, padding, bias=False)
)
self.conv.append(nn.BatchNorm2d(current_out))
self.conv.append(nn.LeakyReLU(0.2))
self.conv.append(nn.Dropout(0.3))
current_in = current_out
current_out *= 2
current_out = current_out // 2
self.conv = nn.Sequential(*self.conv)
self.fc = nn.Linear(current_out * 2 * 2, 1)
self.aux = nn.Linear(current_out * 2 * 2, 64)
self.flatten = nn.Flatten()
self.activation = nn.Sigmoid()
def forward(self, x):
x = self.conv(x)
x_aux = self.aux(self.flatten(x))
x = self.activation(self.fc(self.flatten(x)))
return x, x_aux
class VAEGAN(nn.Module):
def __init__(self, input_shape, z_dim):
super(VAEGAN, self).__init__()
c, h, w = input_shape
self.encoder = Encoder(c, z_dim)
self.decoder = Decoder(z_dim, (h, w))
self.discriminator = Discriminator(c)
def forward(self, x):
mu, log_var = self.encoder(x)
eps = torch.randn_like(mu)
std = torch.exp(0.5 * log_var)
z = mu + eps * std # z=Enc(x)
x_rec = self.decoder(z) # rec=Dec(z)
z_p = torch.randn_like(z)
x_p = self.decoder(z_p) # x_p=Dec(z_p)
dis_x, dis_x_aux = self.discriminator(x)
dis_x_rec, dis_x_rec_aux = self.discriminator(x_rec)
dis_x_p, dis_x_p_aux = self.discriminator(x_p)
return dis_x, dis_x_rec, dis_x_p, dis_x_aux, dis_x_rec_aux, dis_x_p_aux, mu, log_var
img_size = 28
batch_size = 32
dataloader = DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[
transforms.Resize(img_size),
transforms.ToTensor(),
]
),
),
batch_size=batch_size,
shuffle=True,
)
z_dim = 16
vaegan = VAEGAN((1, img_size, img_size), z_dim)
opt_enc = optim.Adam(vaegan.encoder.parameters(), lr=3e-4)
opt_dec = optim.Adam(vaegan.decoder.parameters(), lr=3e-4)
opt_dis = optim.Adam(vaegan.discriminator.parameters(), lr=3e-4)
epochs = 100
gamma = 0.3
for epoch in range(epochs):
train_loss = 0
for i, (imgs, targets) in enumerate(dataloader):
with torch.autograd.detect_anomaly(): # to follow the trace back to the problematic tensor
# soft labels
fake = torch.full_like(targets, 0.1).unsqueeze(1).float()
real = torch.full_like(targets, 0.9).unsqueeze(1).float()
mu, log_var = vaegan.encoder(imgs)
eps = torch.randn_like(mu)
std = torch.exp(0.5 * log_var)
z = mu + eps * std
x_rec = vaegan.decoder(z)
z_p = torch.randn_like(z)
x_p = vaegan.decoder(z_p)
dis_x, _ = vaegan.discriminator(imgs)
dis_x_rec, _ = vaegan.discriminator(x_rec.detach())
dis_x_p, _ = vaegan.discriminator(x_p.detach())
# 1. Train Discriminator
opt_dis.zero_grad()
gan_loss = F.binary_cross_entropy(dis_x, real) + F.binary_cross_entropy(dis_x_rec, fake) + F.binary_cross_entropy(dis_x_p, fake)
gan_loss.backward()
nn.utils.clip_grad_norm_(vaegan.discriminator.parameters(), 5)
opt_dis.step()
# 2. Get discriminator features for generator training (requires fresh forward pass)
dis_x, dis_x_aux = vaegan.discriminator(imgs)
dis_x_rec, dis_x_rec_aux = vaegan.discriminator(x_rec)
# 3. Train Encoder
opt_enc.zero_grad()
kld = -0.5 * torch.sum(1 + log_var - torch.pow(mu, 2) - torch.exp(log_var))
mse = F.mse_loss(dis_x_aux, dis_x_rec_aux)
enc_loss = kld + mse
enc_loss.backward(retain_graph=True) # Need to retain for decoder training
nn.utils.clip_grad_norm_(vaegan.encoder.parameters(), 5)
opt_enc.step()
# 4. Train Decoder/Generator
opt_dec.zero_grad()
gen_loss = F.binary_cross_entropy(dis_x_rec, real)
dec_loss = gamma * mse + gen_loss
dec_loss.backward() # this raises the tensor version error
nn.utils.clip_grad_norm_(vaegan.decoder.parameters(), 5)
opt_dec.step()
print(f"Epoch {epoch} Batch {100*i/len(dataloader):.2f}% Enc loss {enc_loss.item():.3f} Dec loss {dec_loss:.3f} Dis loss {gan_loss.item():.3f}\n", end="")
The traceback leads to the encoder and says I have a in-place operation. Could it be related to the Flatten? Or to me using “stale” data when training after the second pass?
Thanks in advance!
Edit: sorry for the very long code block but I wanted to include all possible errors. I tried this training procedure with simpler networks (1D data) and I get no errors so I think it may come from the network and not the training.