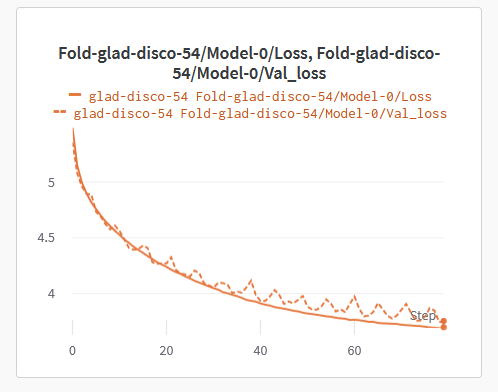
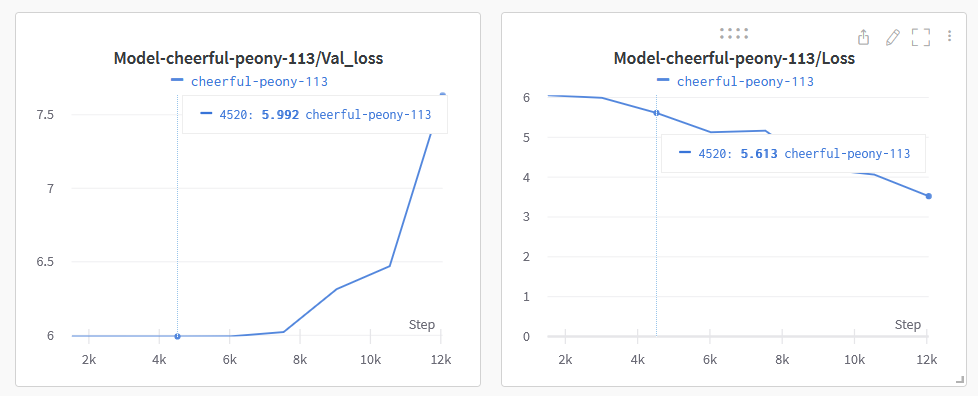
I was trying to add DDP to my implementation, the training is just fine. but when I validate the model the accuracy is not improving. when I train using DP the validation is improving just fine.
The following is my implementation:
import torch
from torch.utils.data import DataLoader
from model import SBERT
from trainer import ConvEntion
import pandas as pd
import torchvision
import wandb
import utile
import configuration as cf
from torch.utils.data.distributed import DistributedSampler
import torch.multiprocessing as mp
import torch.distributed as dist
from torchvision.transforms import (
Compose,
Lambda,
RandomResizedCrop,
RandomCrop,
RandomHorizontalFlip,
CenterCrop,
Normalize
)
utile.setup_seed(123)
def modelTrain(rank, config, run, world_size):
# print(f"RANK {rank}: before init_process_group")
utile.setup(world_size,rank=rank)
print("Loading Data sets...")
train_transform = Compose([
Lambda(lambda x: x / 255.0),
RandomResizedCrop(200, (0.08, 1.0), (0.75, 1.3333333333333333)),
RandomHorizontalFlip(p=0.5),
Normalize((0.48145466, 0.4578275, 0.40821073),(0.229, 0.224, 0.225))
])
test_transform = Compose([
Lambda(lambda x: x / 255.0),
Normalize((0.48145466, 0.4578275, 0.40821073),(0.229, 0.224, 0.225)),
CenterCrop(200),
])
train_dataset = torchvision.datasets.Kinetics(root=config.root_path, frames_per_clip=config.frames_per_clip,
step_between_clips=config.step_between_clips, num_workers = config.worker_k, split='train', transform= train_transform, output_format = 'TCHW' )
valid_dataset = torchvision.datasets.Kinetics(root=config.root_path, frames_per_clip=config.frames_per_clip,
step_between_clips=config.step_between_clips, num_workers = config.worker_k, split='val', transform= test_transform, output_format = 'TCHW')
train_sampler = DistributedSampler(train_dataset, num_replicas=world_size, rank=rank, shuffle=False, drop_last=False)
print("Creating Dataloader...")
pin_memory = False
train_data_loader = DataLoader(train_dataset, batch_size=config.batch_size, pin_memory=pin_memory, num_workers=config.worker,
drop_last=False, shuffle=False, sampler=train_sampler, collate_fn=utile.collate_fn)
valid_data_loader = DataLoader(valid_dataset, batch_size=16, pin_memory=pin_memory, num_workers=config.worker,
drop_last=False, shuffle=False, collate_fn=utile.collate_fn)
print(f'N train: {len(train_data_loader)*config.batch_size} ')
print('--------------------------------')
# run= 'test'
print("Loading Conv-BERT model parameters...")
sbertFine = SBERT( hidden=config.hidden_size, n_layers=config.layers,
attn_heads=config.attn_heads, dropout=config.dropout)
print("Creating ConvEntion...")
trainerFine = ConvEntion(sbertFine, config.num_classes,
train_dataloader=train_data_loader,
valid_dataloader=valid_data_loader, rank=rank,
lr=config.learning_rate, fold=run.name,
preTrain=True, cuda_devices=0)
print("Training ConvEntion...")
OAAccuracy = 0
for epoch in range(config.epochs):
train_OA, train_loss = trainerFine.train(epoch)
if rank == 0:
valid_loss, valid_OA = trainerFine._validate()
wandb.log({f'Model-{run.name}/Loss': train_loss, f'Model-{run.name}/Val_loss': valid_loss, f'Model-{run.name}/OAccuracy': train_OA, f'Model-{run.name}/Val_OAccuracy': valid_OA })
if OAAccuracy < valid_OA:
OAAccuracy = valid_OA
trainerFine.save(epoch, config.finetune_path)
utile.cleanup()
run.finish()
if __name__ == "__main__":
config = cf.Config()
# Configuration options
# Dataframes to store the stats
torch.manual_seed(42)
run = wandb.init(project='ConvEntionKineticsDDP')
world_size = 5
mp.spawn(
modelTrain,
args=(config, run, world_size),
nprocs=world_size
)
Trainer:
class ConvEntion:
def __init__(self, sbert: SBERT, num_classes: int,
train_dataloader: DataLoader, valid_dataloader: DataLoader, rank,
lr: float = 1e-3, with_cuda: bool = True,
cuda_devices=None, log_freq: int = 100, fold=0, modelId=0, preTrain=False, weights=None):
self.fold = fold
self.sbert = sbert
self.modelId = modelId
self.preTrain = preTrain
self.rank = rank
self.train_dataloader = train_dataloader
self.valid_dataloader = valid_dataloader
self.num_classes = num_classes
gc.collect()
with torch.cuda.device('cuda'):
torch.cuda.empty_cache()
self.model =ConvEntionClassification(sbert, num_classes).to(rank)
# calculate the number of parameters in the model
param = filter(lambda p: p.requires_grad, self.model.parameters())
param = sum([np.prod(p.size()) for p in param]) / 1_000_000
print('Trainable Parameters: %.3fM' % param)
# init the model
self.model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(self.model)
self.model = DDP(self.model, device_ids=[rank], output_device=rank, find_unused_parameters=True)
# init the optimizer for the model
self.optim = AdamW(self.model.parameters(), lr=lr, weight_decay=0.05)
self.scheduler = lr_scheduler.CosineAnnealingLR(self.optim, T_max=200, eta_min=1e-6)
# criterion
self.criterion = nn.CrossEntropyLoss()
def train(self, epoch):
train_loss = 0.0
counter = 0
total_correct = 0
total_element = 0
self.train_dataloader.sampler.set_epoch(epoch)
matrix = np.zeros([self.num_classes, self.num_classes])
for data in self.train_dataloader:
clip, label = data["video"], data["label"]
classification = self.model(clip.float(), None, None,None )
loss = self.criterion(classification, label.long().to(self.rank))
classification_target = label.to(self.rank)
self.optim.zero_grad()
loss.backward()
self.optim.step()
train_loss += loss.item()
classification_result = classification.argmax(dim=-1)
correct = classification_result.eq(classification_target).sum().item()
total_correct += correct
total_element += label.nelement()
Live_OA = total_correct / total_element * 100
if self.rank==0:
wandb.log({f'Fold-{self.fold}/OA': Live_OA,f'Fold-{self.fold}/lr': lr })
for row, col in zip(classification_result, classification_target):
matrix[row, col] += 1
counter += 1
self.scheduler.step()
train_loss /= counter
train_OA = total_correct / total_element * 100
return train_OA, train_loss
def _validate(self):
with torch.no_grad():
self.model.eval()
valid_loss = 0.0
counter = 0
total_correct = 0
total_element = 0
matrix = np.zeros([self.num_classes, self.num_classes])
for data in self.valid_dataloader:
clip, label = data["video"], data["label"]
classification = self.model(clip.float(), None, None,None )
loss = self.criterion(classification, label.long().to(self.rank))
valid_loss += loss.item()
classification_result = classification.argmax(dim=-1)
classification_target = label.to(self.rank)
correct = classification_result.eq(classification_target).sum().item()
total_correct += correct
total_element += label.nelement()
for row, col in zip(classification_result, classification_target):
matrix[row, col] += 1
counter += 1
valid_loss /= counter
valid_OA = total_correct / total_element * 100
self.model.train()
return valid_loss, valid_OA