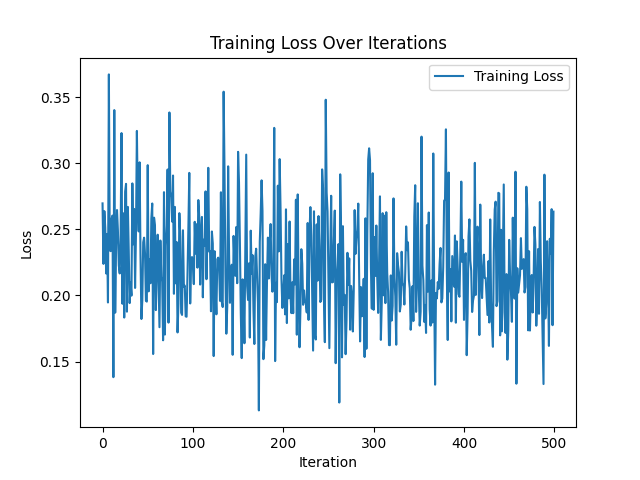
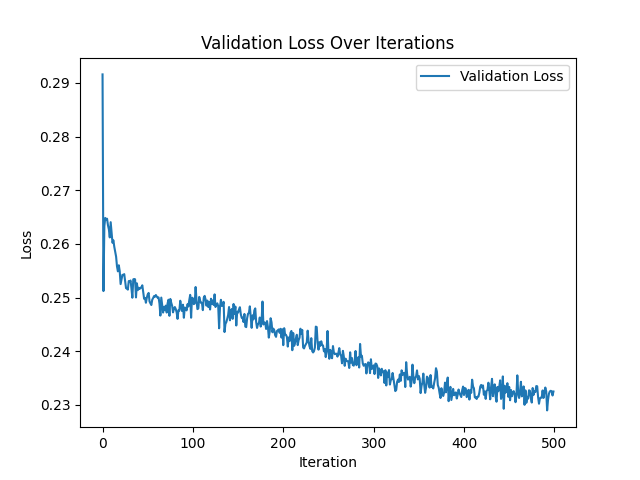
Hi, while training my model I can see the validation loss decrease but the training loss fluctuate. I’ve tried increasing the batch size (still doesn’t get any better), batch norm and L2 reg. Thanks in advance.
Model:
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.batch_norm = nn.BatchNorm1d(118)
self.conv1 = nn.Conv1d(118, 50, 5)
self.pool = nn.MaxPool1d(2, 2)
self.conv2 = nn.Conv1d(50, 50, 5)
self.fc1 = nn.Linear(50 * 47, 100)
self.fc2 = nn.Linear(100, 90)
self.fc3 = nn.Linear(90, 118)
def forward(self, input_seq):
x = copy.deepcopy(input_seq)
x = self.batch_norm(x)
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = x.view(-1, 50 * 47)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
output = F.softplus(x)
# Masking the output
output_mask = np.count_nonzero(input_seq.numpy(), axis=2) // 200
output_mask = torch.FloatTensor(output_mask).to(input_seq.device) # changes added here
output = output * output_mask
# Normalization
output_sum = output.sum(dim=1, keepdim=True)
output = output / output_sum
return output
def custom_loss(output, target):
distance = (output - target).pow(2).sum(1).sqrt()
return torch.mean(distance)
Training Loop:
training_loader = torch.utils.data.DataLoader(training_dataset, batch_size=256, shuffle=True)
testing_loader = torch.utils.data.DataLoader(testing_dataset, batch_size=10, shuffle=False)
model = Model()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-2)
num_epochs = 500
print_every = 1
plot_every = 1
all_losses = []
validation_losses = [] # Store validation losses
for epoch in track(range(num_epochs), description="Training the model..."):
for i, data in enumerate(training_loader):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
# print("training_outputs", outputs, outputs.shape, outputs[0].sum())
loss = custom_loss(outputs, labels)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step()
# Validation loss calculation
model.eval()
with torch.no_grad():
validation_loss = 0
for val_inputs, val_labels in testing_loader:
val_outputs = model(val_inputs)
validation_loss += custom_loss(val_outputs, val_labels).item()
validation_loss /= len(testing_loader)
validation_losses.append(validation_loss)
model.train()
if (epoch + 1) % print_every == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}], Training Loss: {loss.item()}, Validation Loss: {validation_loss}")
if (epoch + 1) % plot_every == 0:
all_losses.append(loss.item())