I’m training a simple self-attention model and I’m obtaining some good results on the validation set (in terms of accuracy, MCC, recall and precision). I’ve done this doing a train/test split several times. The only problem is that the validation loss is extremely large compared to the training loss. I’m attaching an example but they more or less all look the same:
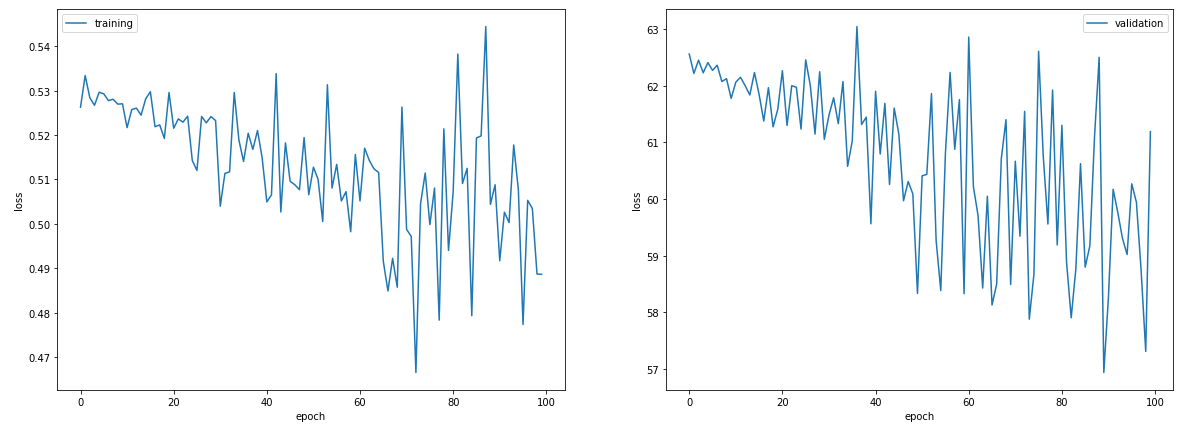
If I train it for like 500 epochs, the validation loss keep decreasing nicely (while the training loss oscillates more) but it’s always much larger. Has anyone seen something similar before?
I’m also attaching the training and validation loop:
training_loss = []
val_loss = []
for epoch in range(1, num_epochs+1):
#print(f'EPOCH: {epoch}...')
model.train()
avg_loss = 0.0
for idx, batch in enumerate(train_loader):
smiles, labels = batch[0].to(device), batch[1].to(device)
# Fit
optimizer.zero_grad()
out = model(smiles)
loss = criterion(out, labels)
avg_loss =+ loss.item() * smiles.size(0)
loss.backward()
optimizer.step()
training_loss.append(avg_loss / len(train_loader))
# Validation
model.eval()
with torch.no_grad():
avg_loss = 0.0
y_pred = []
y_val = []
for idx, batch in enumerate(val_loader):
smiles, labels = batch[0].to(device), batch[1].to(device)
out = model(smiles)
y_val.extend(list(labels.detach().cpu().numpy()))
y_pred.extend(list(torch.argmax(out, dim=1).detach().cpu().numpy()))
loss = criterion(out, labels)
avg_loss =+ loss.item() * smiles.size(0)
val_loss.append(avg_loss / len(val_loader))
