Hi,
im trading my model, and the validation loss seems to be way smaller than the training loss. So at test time the model does not perform well. im not sure why that is. Please any suggestions?
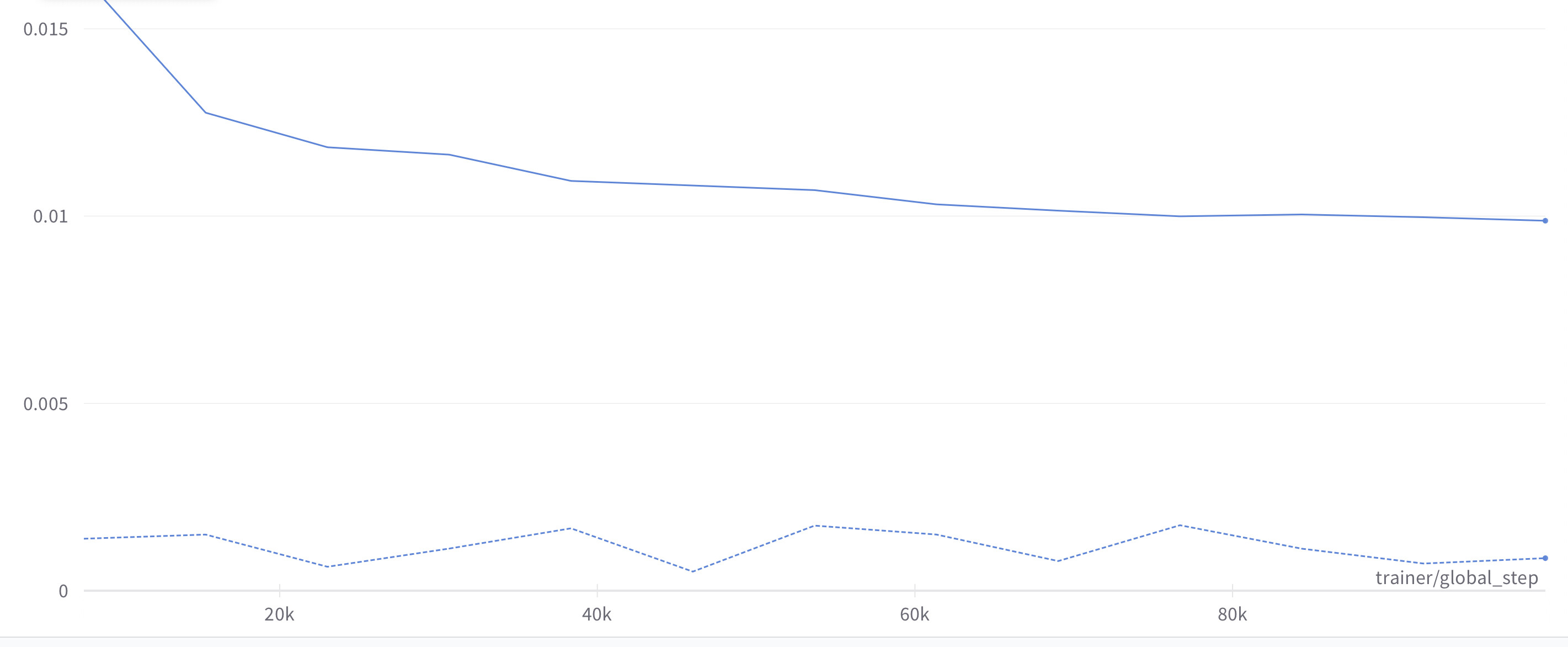
Below is the image of both losses. The top is the training loss while the bottom is the validation loss.
Thanks!
Perhaps you’re computing your loss with sum() (instead of mean()) and
your validation batch size is smaller than your training batch size so summing
over fewer batch elements gives you a smaller loss.
Perhaps you’re using model.train() and model.eval() and, for example,
turning on such things as Dropout layers makes the performance of your
model worse in training mode.
Perhaps the character of your evaluation dataset is different than that of
your training set. If your evaluation dataset happened to contain a lot more
“easy” data samples than your training dataset, those easy samples could
lead to a lower loss.
Or perhaps you just have a bug in your code somewhere.
What happens if you pretend that your training dataset is your validation
dataset and use it to compute your “validation” loss. What size loss values
do you get then?