The following is my training loop:
def train_one_epoch(model,train_dataloader,optimizer,criterion):
running_loss = 0
batches_loss = []
for i,j in enumerate(train_dataloader):
X = j[0].to(device)
true_rul = j[1].to(device)
optimizer.zero_grad()
pred_rul = model(X)
loss = criterion(pred_rul,true_rul)
loss.backward()
optimizer.step()
# running_loss += loss.item()
# if i % 100 == 99:
batches_loss.append(loss.item()) #average loss batch
# print(f'Batch {i + 1} loss {last_loss}')
average_epoch_train_loss = np.mean(batches_loss)
return average_epoch_train_loss,model
def train(model,epoch_number,train_dataloader,val_dataloader,optimizer,criterion,scheduler = None,scheduling_epoch = None,scheduling_interval = 10):
epoch_train_loss = []
epoch_val_loss = []
best_val_loss = 1000000
for epoch in range(epoch_number):
model.train(True)
avg_train_loss,model = train_one_epoch(model,
train_dataloader,
optimizer,criterion)
model.eval()
with torch.no_grad():
val_loss = []
for i,j in enumerate(val_dataloader):
X = j[0].to(device)
true_rul = j[1].to(device)
pred_rul = model(X)
loss = criterion(pred_rul,true_rul)
val_loss.append(loss.item())#adding average batch loss
#average loss over all batches
avg_val_loss = np.mean(val_loss)
#validation loss for epoch
epoch_val_loss.append(avg_val_loss)
if scheduler:
if (epoch + 1)>= scheduling_epoch:
if ((epoch + 1) - scheduling_epoch)%scheduling_interval == 0:
print("Changing LR")
print(f'Old LR : {optimizer.param_groups[0]["lr"]}')
scheduler.step()
print(f'New LR : {optimizer.param_groups[0]["lr"]}')
print(f"--------Epoch {epoch}--------")
print(f"--------Epoch Training Loss :{avg_train_loss:.2f}-------")
print(f"--------Epoch Validation Loss :{avg_val_loss:.2f}-----------")
epoch_train_loss.append(avg_train_loss)
return model,epoch_train_loss,epoch_val_loss
And this is my Training/Validation loss curve:
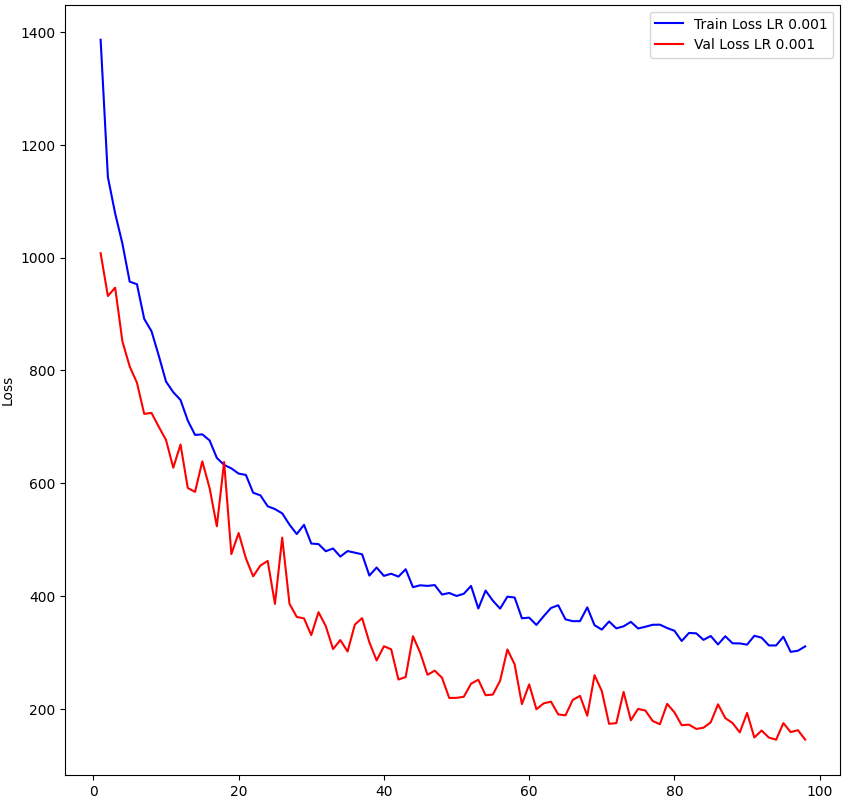
For calculating my validation loss, I am first training on the entire training dataset and calculating the average epoch loss. Subsequently I make my model into evaluation model (freeze the training process) and then apply it on the validation dataset to calculate the validation loss. The training loss is being calculated while the model is learning, hence there will be higher loss values at early batches of the epoch. And in the validation loss calculation, the model is “better” than what was used in the early batches of the training time for that epoch, as the model has learnt at the end of that epoch. Can this cause the validation loss to be lower than my training loss?
I also checked the distribution of data for train and validation and it seems to have similar distribution too.
Any help is appreciated