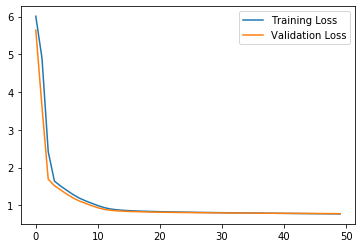
Hello everybody, I’m writing here to ask some opinions about my situation. I’ve been using pytorch and pytorch geometric for my deep learning architecture on a multi-regression with two targets. Everything looks pretty ok, except that, during training process, my validation loss keeps being lower than training one.
I’m attaching here my train and validation for loops:
def train_model(model, train_loader,val_loader,lr):
"Model training"
epochs=50
model.train()
train_losses = []
val_losses = []
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5)
#Reduce learning rate if no improvement is observed after 10 Epochs.
#scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, verbose=True)
for epoch in range(epochs):
loss_batches=[]
for data in train_loader:
y_pred = model.forward(data)
loss1 = criterion(y_pred[:, 0], data.y[0])
loss2 = criterion(y_pred[:,1], data.y[1])
train_loss = 0.8*loss1+0.2*loss2
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
loss_batches.append(train_loss.item())
train_losses.append(sum(loss_batches)/len(loss_batches))
with torch.no_grad():
loss_batches=[]
for data in val_loader:
y_val = model.forward(data)
loss1 = criterion(y_val[:,0], data.y[0])
loss2 = criterion(y_val[:,1], data.y[1])
val_loss = 0.5*loss1+0.5*loss2
loss_batches.append(val_loss.item())
val_losses.append(sum(loss_batches)/len(loss_batches))
print(f'Epoch: {epoch}, train_loss: {train_losses[epoch]:.3f} , val_loss: {val_losses[epoch]:.3f}')
return train_losses, val_losses
I’m perplexed about the correctness of my methodology, especially about the indentation of my code, but I really can’t figure out what can be wrong. I’m also attaching the information printed out during training for each epoch: (as you can see from the code I’m displaying a final train/val loss that is just the average of all train/val losses of all batches)
Epoch: 0, train_loss: 7.378 , val_loss: 5.690
Epoch: 1, train_loss: 5.618 , val_loss: 3.611
Epoch: 2, train_loss: 2.789 , val_loss: 1.831
Epoch: 3, train_loss: 2.037 , val_loss: 1.623
Epoch: 4, train_loss: 1.850 , val_loss: 1.502
Epoch: 5, train_loss: 1.682 , val_loss: 1.400
Epoch: 6, train_loss: 1.536 , val_loss: 1.331
Epoch: 7, train_loss: 1.440 , val_loss: 1.295
Epoch: 8, train_loss: 1.387 , val_loss: 1.273
Epoch: 9, train_loss: 1.356 , val_loss: 1.256
Epoch: 10, train_loss: 1.335 , val_loss: 1.242
Epoch: 11, train_loss: 1.319 , val_loss: 1.230
Epoch: 12, train_loss: 1.306 , val_loss: 1.218
Epoch: 13, train_loss: 1.295 , val_loss: 1.206
Epoch: 14, train_loss: 1.284 , val_loss: 1.192
Epoch: 15, train_loss: 1.273 , val_loss: 1.175
Epoch: 16, train_loss: 1.261 , val_loss: 1.157
Epoch: 17, train_loss: 1.250 , val_loss: 1.139
Epoch: 18, train_loss: 1.239 , val_loss: 1.119
Epoch: 19, train_loss: 1.227 , val_loss: 1.098
Epoch: 20, train_loss: 1.216 , val_loss: 1.076
Epoch: 21, train_loss: 1.204 , val_loss: 1.053
Epoch: 22, train_loss: 1.192 , val_loss: 1.030
Epoch: 23, train_loss: 1.181 , val_loss: 1.009
Epoch: 24, train_loss: 1.171 , val_loss: 0.989
Epoch: 25, train_loss: 1.161 , val_loss: 0.972
Epoch: 26, train_loss: 1.153 , val_loss: 0.958
Epoch: 27, train_loss: 1.146 , val_loss: 0.946
Epoch: 28, train_loss: 1.140 , val_loss: 0.937
Epoch: 29, train_loss: 1.135 , val_loss: 0.930
Epoch: 30, train_loss: 1.131 , val_loss: 0.924
Epoch: 31, train_loss: 1.128 , val_loss: 0.919
Epoch: 32, train_loss: 1.124 , val_loss: 0.915
Epoch: 33, train_loss: 1.122 , val_loss: 0.911
Epoch: 34, train_loss: 1.119 , val_loss: 0.908
Epoch: 35, train_loss: 1.117 , val_loss: 0.905
Epoch: 36, train_loss: 1.114 , val_loss: 0.902
Epoch: 37, train_loss: 1.112 , val_loss: 0.899
Epoch: 38, train_loss: 1.110 , val_loss: 0.897
Epoch: 39, train_loss: 1.108 , val_loss: 0.894
Epoch: 40, train_loss: 1.106 , val_loss: 0.892
Epoch: 41, train_loss: 1.105 , val_loss: 0.890
Epoch: 42, train_loss: 1.103 , val_loss: 0.888
Epoch: 43, train_loss: 1.102 , val_loss: 0.886
Epoch: 44, train_loss: 1.100 , val_loss: 0.885
Epoch: 45, train_loss: 1.099 , val_loss: 0.883
Epoch: 46, train_loss: 1.097 , val_loss: 0.881
Epoch: 47, train_loss: 1.096 , val_loss: 0.880
Epoch: 48, train_loss: 1.095 , val_loss: 0.878
Epoch: 49, train_loss: 1.093 , val_loss: 0.876
The funny thing is, that apart from this strangeness, the model seems to work, since considering completely new unseen data in my test_loader, the predictions appear to be pretty accurate, and I’m able to get to an r2_score of 0.52 for the first target and 0.72 for the second one. I appreciate anybody providing his/her opinion about this situation 
Many thanks,
Federico