Finally got fed up with tensorflow and am in the process of piping a project over to pytorch. So far I’ve found pytorch to be different but MUCH more intuitive.
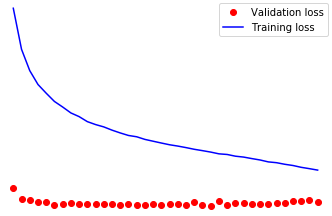
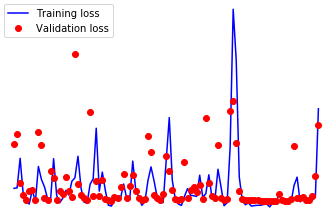
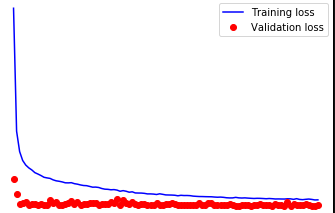
One of my nets is a good old fashioned autoencoder I use for anomaly detection of unlabelled data. I’ve set it up to periodically report my current training and validation loss and have come across a head scratcher. My training loss improves about what I’d expect (although faster would be great), but my validation loss remains essentially the same. I’ve perused the forums here and can’t find anything that helps. Admittedly, while I can build nets pretty well in tensorflow, this could just be a stupid error on my part. I know it isn’t the data as the same data, formatted exactly the same way performs well in tensorflow. And I have… a lot of data. So no issues there. I’ll post a sample below of the minimum working code that reproduces the error.
If you want machine specs, I’d be happy to post if they’re relevant (three gpus).
Thanks!
Formatting data and defining the autoencoder
train_data = torch.from_numpy(df[fullData].values[:train])
val_data = torch.from_numpy(df[fullData].values[validate:])
batchsize = 1024
train_iter = DataLoader(dataset=train_data, batch_size=batchsize, shuffle=True)
val_iter = DataLoader(dataset=val_data, batch_size=batchsize, shuffle=True)
class Model(nn.Module):
def __init__(self, input_size, output_size, droprate):
super(Model, self).__init__()
self.en1 = nn.Linear(input_size, 640)
self.dp1 = nn.Dropout(droprate)
self.en2 = nn.Linear(640, 320)
self.dp2 = nn.Dropout(droprate)
self.en3 = nn.Linear(320, 160)
self.dp3 = nn.Dropout(droprate)
self.en4 = nn.Linear(160, 80)
self.dp4 = nn.Dropout(droprate)
self.dec1 = nn.Linear(80, 160)
self.dp5 = nn.Dropout(droprate)
self.dec2 = nn.Linear(160, 320)
self.dp6 = nn.Dropout(droprate)
self.dec3 = nn.Linear(320, 640)
self.dp7 = nn.Dropout(droprate)
self.dec4 = nn.Linear(640, output_size)
def forward(self, ins):
x = F.elu(self.en1(ins))
x = self.dp1(x)
x = F.elu(self.en2(x))
x = self.dp2(x)
x = F.elu(self.en3(x))
x = self.dp3(x)
x = F.elu(self.en4(x))
x = self.dp4(x)
x = F.elu(self.dec1(x))
x = self.dp5(x)
x = F.elu(self.dec2(x))
x = self.dp6(x)
x = F.elu(self.dec3(x))
x = self.dp7(x)
output = F.elu(self.dec4(x))
return output
Aaaaand doing the training
model = Model(input_size, output_size, 0.5)
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.0001, weight_decay=0.00001)
num_epochs = 10
iters = 0
model = model.double()
validate = 100
best_val_loss = 100
vals = []
losses = []
for epoch in range(num_epochs):
for batch_idx, batch in enumerate(loader):
model.train()
optimizer.zero_grad()
iters += 1
inputs = batch.to(device)
output = model(inputs)
train_loss = criterion(output, inputs)
train_loss.backward()
optimizer.step()
if iters % validate == 0:
val_loss = 0
model.eval()
with torch.no_grad():
for val in (val_iter):
val = val.to(device)
answer = model(val)
val_loss = criterion(answer, val)
vals.append(val_loss.item())
iterations.append(iters)
losses.append(train_loss.item())