def train(epoch,model,device,optimizer,loss_fn,dataloader):
model.train()
running_loss = 0.0
pbar = tqdm(enumerate(dataloader),total=len(dataloader))
for i,(img,label) in pbar:
opt.zero_grad()
img = img.to(device).float()
label = label.to(device).float()
with torch.cuda.amp.autocast():
logits = model(img)
loss = loss_fn(logits.flatten(),label)
running_loss += loss.item() * img.size(0)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
Epoch_Loss = running_loss/len(dataloader)
writer.add_scalar("Loss/TrainEpoch",Epoch_Loss,epoch)
print(f"Epoch:{epoch} TrainLoss:{Epoch_Loss}")
return Epoch_Loss
def val(epoch,device,model,loss_fn,dataloader):
model.eval()
running_loss=0.0
pbar = tqdm(enumerate(dataloader),total=len(dataloader))
for i,(img,label) in pbar:
img = img.to(device).float()
label = label.to(device).float()
with torch.no_grad():
outputs = model(img)
loss = loss_fn(outputs.flatten(),label)
running_loss += loss.item() * img.size(0)
try:
auc = roc_auc_score(y_true=label.cpu(),y_score=outputs.sigmoid().cpu())
except ValueError as e:
error=e
Epoch_Loss = running_loss/len(dataloader)
writer.add_scalar("Loss/ValEpoch",Epoch_Loss,epoch)
print(f"Epoch: {epoch} Validation Loss: {Epoch_Loss}")
return Epoch_Loss
This is my training and validation loop
Model: Efficientnet B3
Loss: BCEWithLogits
Dataset: Melanoma2020+Melanoma2019 (Highly Imbalanced 85.6% negative samples and just 14.4% positive samples)
optimizer: Adam(lr=0.001,weight_decay=1e-6)
lr_scheduler: ReduceLROnPlateau()
folds: GroupKFold(splits=6)
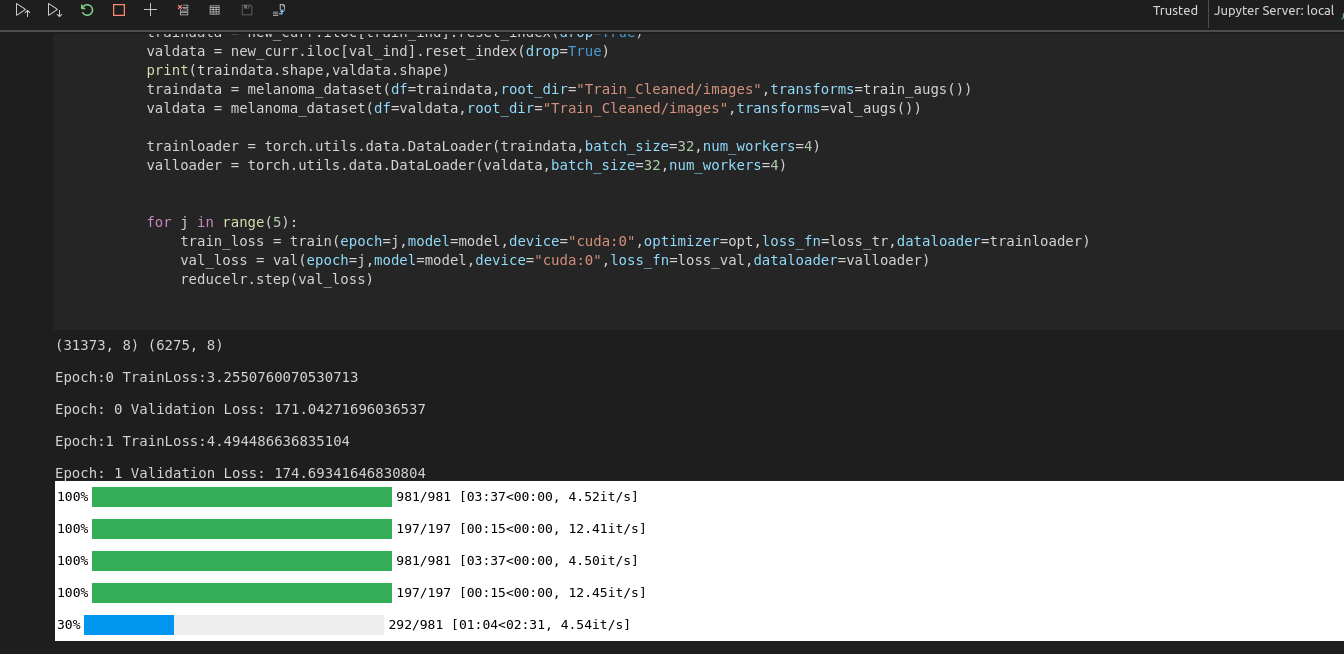
These are my model and other configs, My validation loss is going too high like 214. I wanna know that is there any mistake with my training and validation loop or just tuning my hyper parameters will do. I couldn’t find any improvement in the model. Any help will be appreciated.
Thanks in Advance