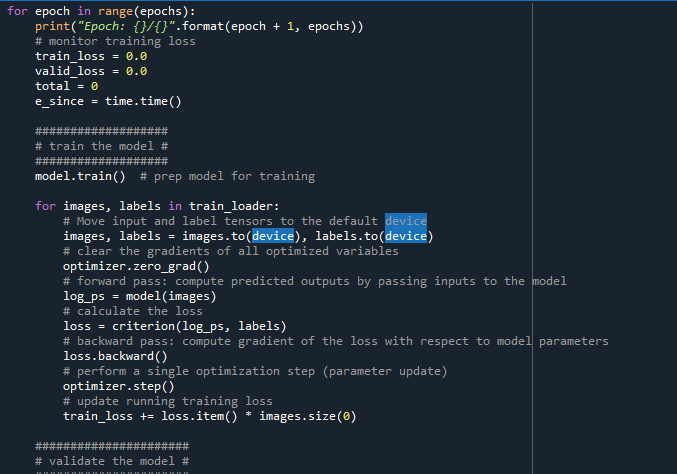
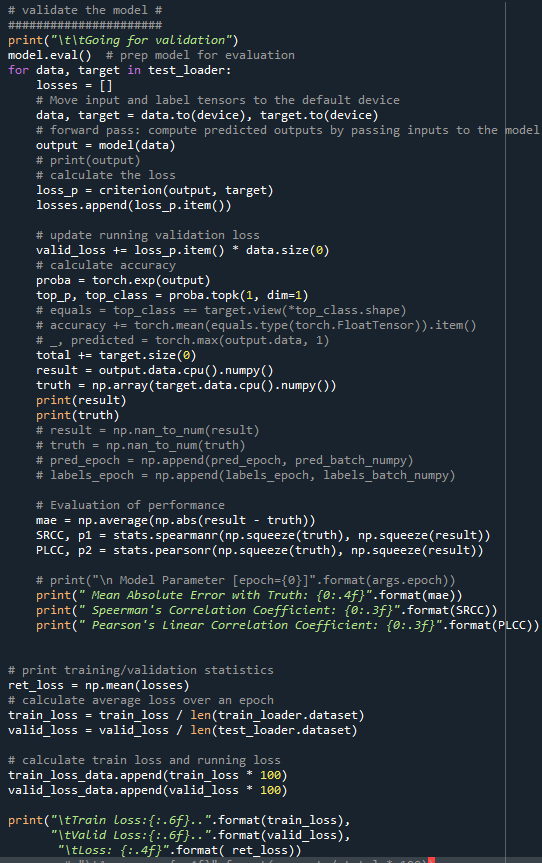
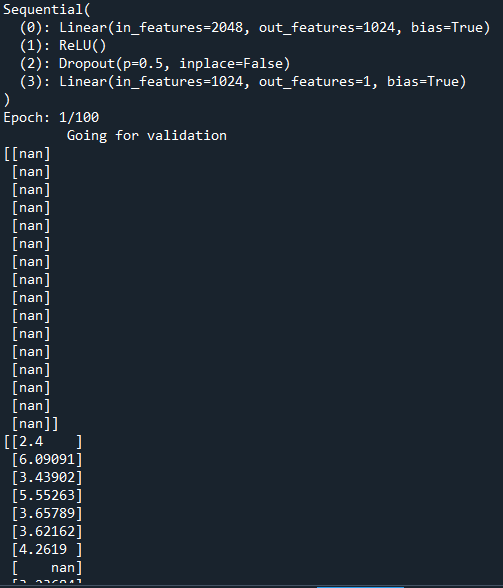
NaNs start resulting from the output of the forward pass step of the model.
Let me post with backticks.
‘’’
def train(model, train_loader, test_loader,
epochs, optimizer, criterion, scheduler=None,
name=“model.pt”, path=None):
# compare overfitted
train_loss_data, valid_loss_data = [], []
# check for validation loss
valid_loss_min = np.Inf
# calculate time
since = time.time()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
for epoch in range(epochs):
print("Epoch: {}/{}".format(epoch + 1, epochs))
# monitor training loss
train_loss = 0.0
valid_loss = 0.0
total = 0
e_since = time.time()
###################
# train the model #
###################
model.train() # prep model for training
for images, labels in train_loader:
# Move input and label tensors to the default device
images, labels = images.to(device), labels.to(device)
print(images)
# clear the gradients of all optimized variables
# forward pass: compute predicted outputs by passing inputs to the model
log_ps = model(images)
# calculate the loss
loss = criterion(log_ps, labels)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update running training loss
train_loss += loss.item() * images.size(0)
######################
# validate the model #
######################
print("\t\tGoing for validation")
model.eval() # prep model for evaluation
for data, target in test_loader:
losses = []
# Move input and label tensors to the default device
data, target = data.to(device), target.to(device)
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# print(output)
# calculate the loss
loss_p = criterion(output, target)
losses.append(loss_p.item())
# update running validation loss
valid_loss += loss_p.item() * data.size(0)
# calculate accuracy
proba = torch.exp(output)
top_p, top_class = proba.topk(1, dim=1)
# equals = top_class == target.view(*top_class.shape)
# accuracy += torch.mean(equals.type(torch.FloatTensor)).item()
# _, predicted = torch.max(output.data, 1)
total += target.size(0)
result = output.data.cpu().numpy()
truth = np.array(target.data.cpu().numpy())
print(result)
print(truth)
# result = np.nan_to_num(result)
# truth = np.nan_to_num(truth)
# pred_epoch = np.append(pred_epoch, pred_batch_numpy)
# labels_epoch = np.append(labels_epoch, labels_batch_numpy)
# Evaluation of performance
mae = np.average(np.abs(result - truth))
SRCC, p1 = stats.spearmanr(np.squeeze(truth), np.squeeze(result))
PLCC, p2 = stats.pearsonr(np.squeeze(truth), np.squeeze(result))
# Display
# print("\n Model Parameter [epoch={0}]".format(args.epoch))
print(" Mean Absolute Error with Truth: {0:.4f}".format(mae))
print(" Speerman's Correlation Coefficient: {0:.3f}".format(SRCC))
print(" Pearson's Linear Correlation Coefficient: {0:.3f}".format(PLCC))
# correct += SRCC.sum().item()
# correct += (stats.spearmanr(truth, result) ).sum().item().cpu().numpy()
# correct += np.sum((stats.spearmanr(predicted.cpu().numpy(), target.cpu().numpy()))).item()
# correct += (predicted == target).sum().item()
# print(correct)
# print training/validation statistics
ret_loss = np.mean(losses)
# calculate average loss over an epoch
train_loss = train_loss / len(train_loader.dataset)
valid_loss = valid_loss / len(test_loader.dataset)
# calculate train loss and running loss
train_loss_data.append(train_loss * 100)
valid_loss_data.append(valid_loss * 100)
print("\tTrain loss:{:.6f}..".format(train_loss),
"\tValid Loss:{:.6f}..".format(valid_loss),
"\tLoss: {:.4f}".format( ret_loss))
# "\tAccuracy: {:.4f}".format(correct / total * 100))
if scheduler is not None:
scheduler.step() # step up scheduler
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('\tValidation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), name)
valid_loss_min = valid_loss
# save to google drive
if path is not None:
torch.save(model.state_dict(), path)
# Time take for one epoch
time_elapsed = time.time() - e_since
print('\tEpoch:{} completed in {:.0f}m {:.0f}s'.format(
epoch + 1, time_elapsed // 60, time_elapsed % 60))
# compare total time
time_elapsed = time.time() - since
print('Training completed in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
# load best model
model = load_latest_model(model, name)
# return the model
return [model, train_loss_data, valid_loss_data]
‘’’
For the model ,
‘’’
- Model loading for transfer learning
densenet = models.densenet161(pretrained=True)
densenet = freeze_parameters(densenet) # freeze feature extraction block
# Change output netowork to Regression
densenet.classifier = regression(in_n=densenet.classifier.in_features)
# check model
print(densenet.classifier)
densenet.to(device)
# - Training Setting
criterion = nn.HuberLoss()
optimizer = optim.Adam(densenet.classifier.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
# - Training
densenet, train_loss, test_loss = train(densenet, train_loader, test_loader, epochs, optimizer, criterion)
check_overfitted(train_loss, test_loss)
# - Save
torch.save(densenet.state_dict(), "data/densenet.pth")
print("Saved Densenet to densenet.pth !")
model = densenet
‘’’