I am really new to pytorch and want to learn lstm for sentence classification. So I coded a lstm shown below( I have pretrained glove embeddings)
class FirstLSTM(nn.Module):
def __init__(self,max_features,max_len,embed_dim,lstm_units,embedding_weights):
super(FirstLSTM,self).__init__()
# the variables are defined outside, so to make use of them in other methods ,
# I am defining them in init..
self.max_features=max_features # vocab size
self.max_len=max_len # sequence length
self.embed_dim=embed_dim # embedding dimension
self.lstm_units=lstm_units # lstm output size
self.num_layers=1 # number of layers in lstm
self.embeddings_matrix=torch.tensor(embedding_weights) # converting them to tensors
self.out=1 # dimension of the output
# now we have defined the embedding layer
# this is the classic way to define.....
# self.embed_layer=nn.Embedding(num_embeddings=self.max_features,
# embedding_dim=self.embed_dim)
# but we have to use a pretrained embedding
# below shows the way for this
self.embed_layer=nn.Embedding.from_pretrained(self.embeddings_matrix,freeze=True)
# lstm layer
# note that I made batch_first = True to replicate with keras...
self.lstm_layer=nn.LSTM(input_size=self.embed_dim,hidden_size=self.lstm_units,
num_layers=self.num_layers,batch_first=True)
self.output_layer=nn.Linear(in_features=self.lstm_units,out_features=self.out)
# this will return the initial hidden state
# The axes semantics are (num_layers, minibatch_size, hidden_dim) even batch_first=True
# as there are two hidden states we will just return the tuple
# https://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html
def initialize_hidden_state(self,batch_size):
return (Variable(torch.zeros((self.num_layers,batch_size,self.lstm_units)).cuda()),
Variable(torch.zeros((self.num_layers,batch_size,self.lstm_units)).cuda()))
def forward(self,X):
batch_shape=X.shape[0]
initial_hidden_state=self.initialize_hidden_state(batch_shape)
X=Variable(X.cuda())
# forward pass
# actually embedding layer needs the tensor of type long, but we pass as an int
# so I will typecaste the long
embeds=self.embed_layer(X.long())
output,h,c=self.lstm_layer(embeds,initial_hidden_state)
# print("after lstm",output.shape)
# output of last layer for each example in batch
output=self.output_layer(output[:,self.max_len-1])
return output
model=FirstLSTM(max_features,max_len,embed_dim,lstm_units,embeddings_matrix)
# pushing the model to gpu
model.cuda()
print(model)
and after this, I am iterating through the epoch loop and batch loop and I landed with this error.
# fixing the optimizer
# you have to paramters to the adam so that it know through it optimize
optimizer=torch.optim.Adam(model.parameters(),lr=1e-3)
# fitting the data
for ep_num in range(epochs):
print("Epoch Number:",ep_num+1)
# iterating through batch
for X,y in train_iterator:
# Zero the gradients before running the backward pass.
optimizer.zero_grad()
# pushing them to gpu
# X=X.cuda()
# y=y.cuda()
y_out=model(X)
print(y_out.shape)
break
break
Note: train iterator is of type dataloader
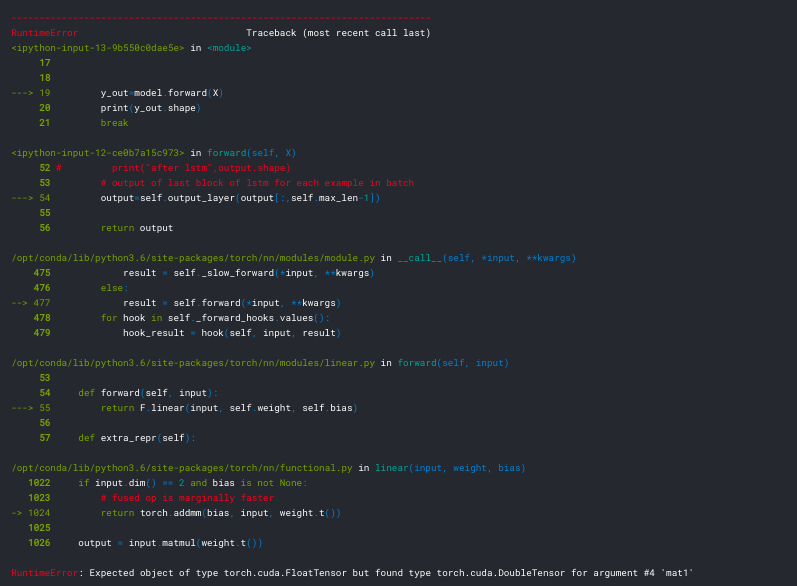
and the error is given below :
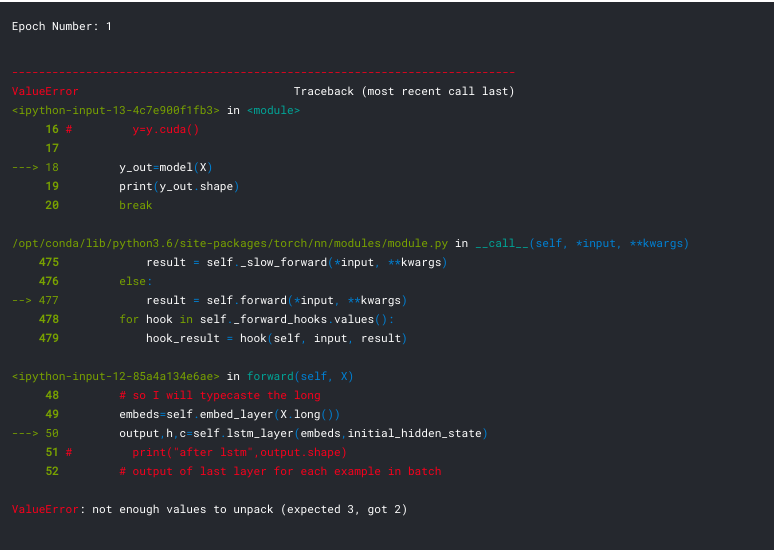
Can I know where the problem is