I’m trying to train a custom model using kohya. I have been running into the same error for over 1 week now. I’ve attached photos of my error message as well as some information about my computer and the applications on it. I’m thinking I have an issue with my setup, but I’m not sure what it is or how to fix it. Any help would be much appreciated!!!
Error Message:
Traceback (most recent call last):
File "D:\Kohya\kohya_ss\sdxl_train_network.py", line 189, in <module>
trainer.train(args)
File "D:\Kohya\kohya_ss\train_network.py", line 242, in train
vae.set_use_memory_efficient_attention_xformers(args.xformers)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\diffusers\models\modeling_utils.py", line 263, in set_use_memory_efficient_attention_xformers
fn_recursive_set_mem_eff(module)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\diffusers\models\modeling_utils.py", line 259, in fn_recursive_set_mem_eff
fn_recursive_set_mem_eff(child)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\diffusers\models\modeling_utils.py", line 259, in fn_recursive_set_mem_eff
fn_recursive_set_mem_eff(child)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\diffusers\models\modeling_utils.py", line 259, in fn_recursive_set_mem_eff
fn_recursive_set_mem_eff(child)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\diffusers\models\modeling_utils.py", line 256, in fn_recursive_set_mem_eff
module.set_use_memory_efficient_attention_xformers(valid, attention_op)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\diffusers\models\attention_processor.py", line 255, in set_use_memory_efficient_attention_xformers
raise ValueError(
ValueError: torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is only available for GPU
Traceback (most recent call last):
File "C:\Users\Allison\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\Allison\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "D:\Kohya\kohya_ss\venv\Scripts\accelerate.exe\__main__.py", line 7, in <module>
File "D:\Kohya\kohya_ss\venv\lib\site-packages\accelerate\commands\accelerate_cli.py", line 47, in main
args.func(args)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\accelerate\commands\launch.py", line 986, in launch_command
simple_launcher(args)
File "D:\Kohya\kohya_ss\venv\lib\site-packages\accelerate\commands\launch.py", line 628, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['D:\\Kohya\\kohya_ss\\venv\\Scripts\\python.exe', './sdxl_train_network.py', '--enable_bucket', '--min_bucket_reso=256', '--max_bucket_reso=2048', '--pretrained_model_name_or_path=D:/Kohya/kohya_ss/sdXL_v10VAEFix.safetensors', '--train_data_dir=C:/Users/Allison/Downloads/jrm/jrm_lora\\img', '--resolution=1024, 1024', '--output_dir=C:/Users/Allison/Downloads/jrm/jrm_lora\\model', '--logging_dir=C:/Users/Allison/Downloads/jrm/jrm_lora\\log', '--network_alpha=64', '--training_comment=jrm', '--save_model_as=safetensors', '--network_module=networks.lora', '--text_encoder_lr=4e-07', '--unet_lr=0.0001', '--network_dim=128', '--output_name=jrm_lora', '--lr_scheduler_num_cycles=1', '--no_half_vae', '--learning_rate=4e-07', '--lr_scheduler=constant_with_warmup', '--lr_warmup_steps=200', '--train_batch_size=1', '--max_train_steps=2001', '--save_every_n_epochs=1', '--mixed_precision=fp16', '--save_precision=fp16', '--cache_latents', '--optimizer_type=Adafactor', '--max_grad_norm=1', '--max_data_loader_n_workers=0', '--bucket_reso_steps=64', '--mem_eff_attn', '--gradient_checkpointing', '--xformers', '--bucket_no_upscale', '--noise_offset=0.0']' returned non-zero exit status 1.
nvcc --version:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Wed_Nov_22_10:30:42_Pacific_Standard_Time_2023
Cuda compilation tools, release 12.3, V12.3.107
Build cuda_12.3.r12.3/compiler.33567101_0
nvidia-smi:
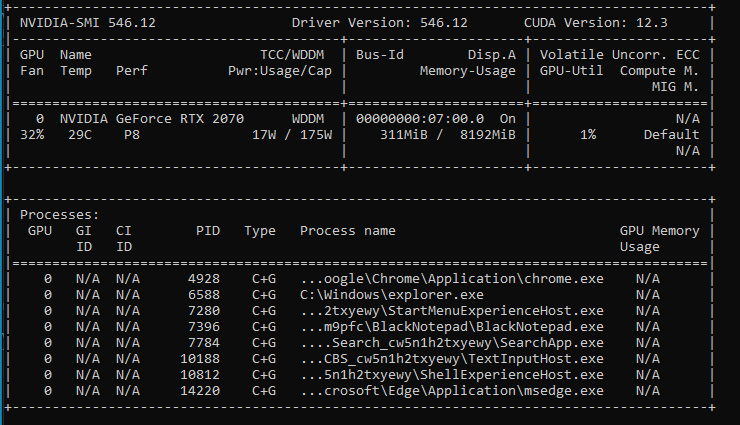
python -m torch.utils.collect_env:
Collecting environment information...
PyTorch version: 2.1.2+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 Home
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19045-SP0
Is CUDA available: True
CUDA runtime version: 12.3.107
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 546.12
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture=9
CurrentClockSpeed=3200
DeviceID=CPU0
Family=107
L2CacheSize=4096
L2CacheSpeed=
Manufacturer=AuthenticAMD
MaxClockSpeed=3200
Name=AMD Ryzen 7 2700 Eight-Core Processor
ProcessorType=3
Revision=2050
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.1.2+cu118
[pip3] torchaudio==2.1.2+cu118
[pip3] torchvision==0.16.2+cu118
[conda] Could not collect