@Aditya_Kumar
Thanks for your reply. Would the evaluation mode cause a difference in the output, or does it have to do with speed and efficiency?
So you are right about the cropping. Since I could not find an equivalent of transforms.CenterCrop(224), I attempted to do the equivalent of this in OpenCV.
Python Code (same as before, haven’t implemented your eval mode suggestion yet):
import torch
import torchvision.models as models
import urllib.request
from PIL import Image
from torchvision import transforms
import numpy as np
def norm_chan(chan, mean, std):
b = (chan - mean) / std
return b
# Load resnet18 model
model = models.resnet18(pretrained = True)
serialize_model = True
if (serialize_model):
example = torch.rand(1, 3, 224, 224)
traced_script_module = torch.jit.trace(model, example)
traced_script_module.save("traced_resnet_model_pretrained.pt")
# sample execution (requires torchvision)
input_image = Image.open("C:\\PyTorchPictureTest\\dog.jpg")
np_im = np.array(input_image)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
import numpy as np
print()
output_cpu = output[0].cpu()
output_numpy = output_cpu.numpy()
for i in range(0, len(output_numpy)):
if ( i%10 == 0):
print("\n")
print(str(output_numpy[i]), end = " ")
print()
C++ code:
#include <torch/script.h>
#include <torch/torch.h>
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <iostream>
#include <memory>
#include <iomanip>
std::string type2str(int type) {
std::string r;
uchar depth = type & CV_MAT_DEPTH_MASK;
uchar chans = 1 + (type >> CV_CN_SHIFT);
switch (depth) {
case CV_8U: r = "8U"; break;
case CV_8S: r = "8S"; break;
case CV_16U: r = "16U"; break;
case CV_16S: r = "16S"; break;
case CV_32S: r = "32S"; break;
case CV_32F: r = "32F"; break;
case CV_64F: r = "64F"; break;
default: r = "User"; break;
}
r += "C";
r += (chans + '0');
return r;
}
int main(int argc, const char* argv[]) {
// Load up GPU stuff
torch::DeviceType device_type;
if (torch::cuda::is_available()) {
std::cout << "CUDA available! Training on GPU." << std::endl;
device_type = torch::kCUDA;
}
else {
std::cout << "Training on CPU." << std::endl;
device_type = torch::kCPU;
}
torch::Device device(device_type);
torch::data::transforms::Normalize<> normalize_transform({ 0.485, 0.456, 0.406 }, { 0.229, 0.224, 0.225 });
torch::jit::script::Module module;
std::cout << "Attempting to load resnet model.." << std::endl;
try {
// Deserialize the ScriptModule from a file using torch::jit::load().
module = torch::jit::load("C:\\PyTorchPictureTest\\Model\\traced_resnet_model_pretrained.pt");
std::cout << "Successfully loaded resnet model" << std::endl;
module.to(at::kCUDA);
std::cout << "Moved model to gpu" << std::endl;
// load image and transform
cv::Mat image;
image = cv::imread("C:\\PyTorchPictureTest\\dog.jpg", cv::IMREAD_COLOR);
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::Mat img_float;
image.convertTo(img_float, CV_32FC3, 1.0f / 255.0f);
// Scale image down
int scaledown_factor = 256;
cv::resize(img_float, img_float, cv::Size(img_float.cols / (img_float.rows / (float)scaledown_factor), scaledown_factor), cv::INTER_NEAREST);
// Emulate transforms.CenterCrop(224)
cv::Rect roi;
int new_width = 224;
int new_height = 224;
roi.x = img_float.size().width / 2 - new_width / 2;
roi.width = new_width;
roi.y = img_float.size().height / 2 - new_height / 2;
roi.height = new_height;
cv::Mat img_cropped = img_float(roi);
// Convert to tensor
auto img_tensor = torch::from_blob(img_cropped.data, { img_cropped.rows, img_cropped.cols, 3 });
img_tensor = img_tensor.permute({ 2, 0, 1 });
std::cout << img_tensor.sizes() << '\n';
// normalize
torch::Tensor img_tensor_norm = normalize_transform(img_tensor).unsqueeze_(0);
std::vector<torch::jit::IValue> inputs;
inputs.push_back(img_tensor_norm.to(at::kCUDA));
// forward pass
torch::Tensor out_tensor = module.forward(inputs).toTensor();
// print output
std::cout << out_tensor << '\n';
}
catch (const c10::Error & e) {
std::cerr << "error loading the model\n";
return -1;
}
std::cout << "ok\n";
}
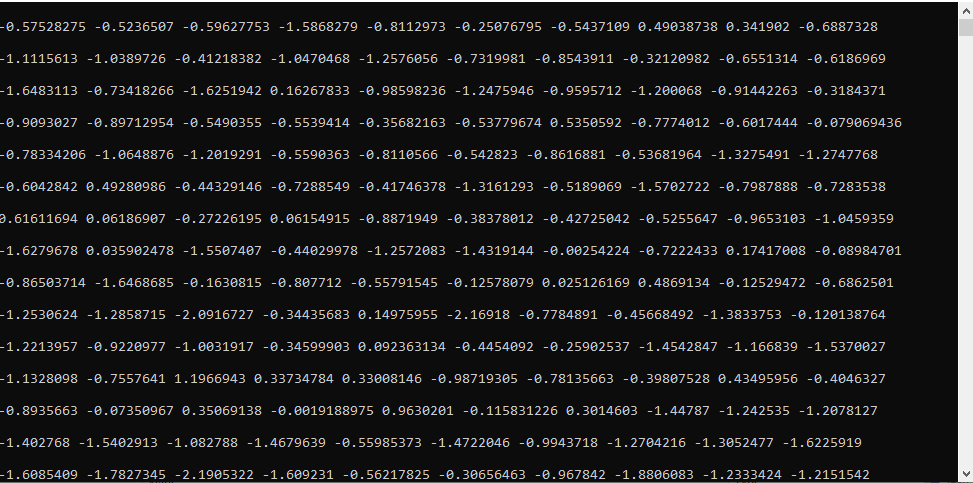
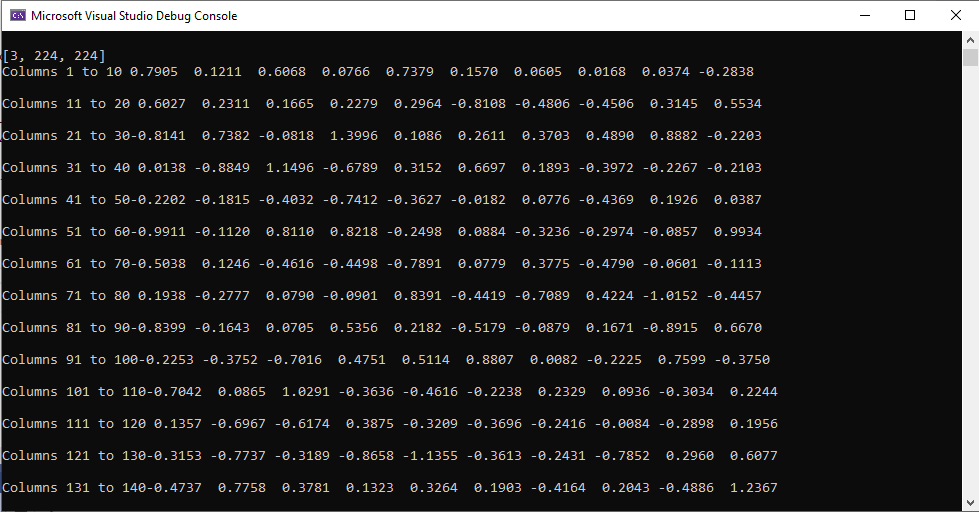
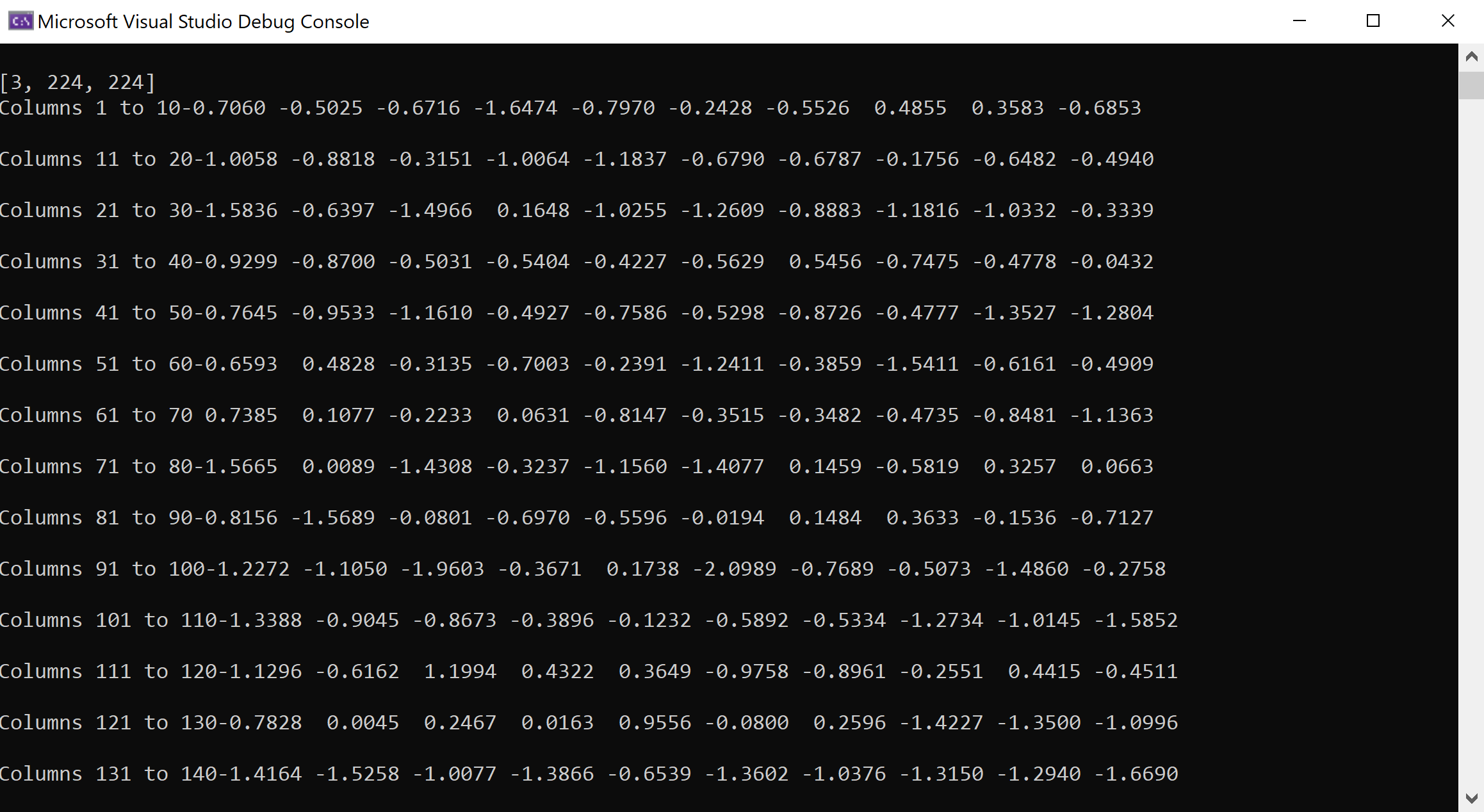
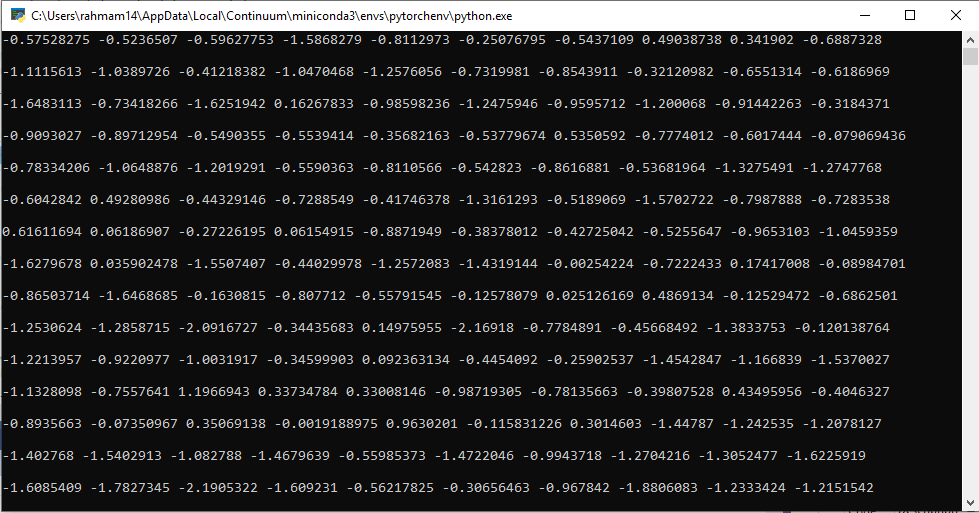
However, even with my changes, there is still a larger different in my outputs than you have suggested should be the case.
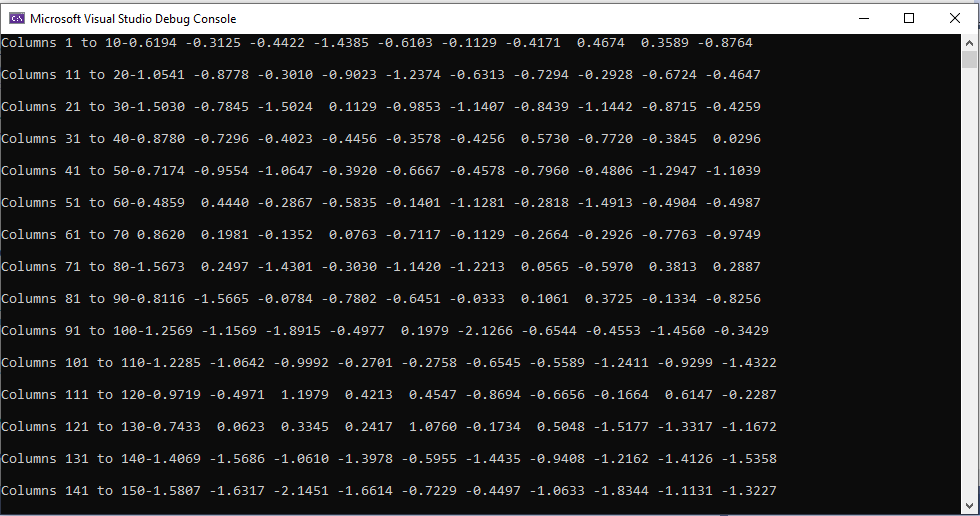
Python Output:
C++ Output:
Regarding the comparing of input tensors, I more wanted to debug the cause of the difference in my outputs: whether it was due to there being a difference of the data going into the model, or whether the model itself produces a different output.
Perhaps I am overcomplicating things a bit for myself. I am relatively new to torchscript and I was trying to experiment with it to ensure that the output in C++ is equivalent to the output in Python. I chose to use ResNet18 since that is the example that was shown on PyTorch’s documentation. Would I be better off doing this exercise with a different network?

{kind=link}