class Sequence_discriminator(nn.Module):
def init(self, kernel_size=3, num_input_channels=3, num_output_channels=64, gru_size=256):
super(Sequence_discriminator, self).init()
# print(“------sequence_discriminator”)
self.num_layers = 6
self.input_channels = num_input_channels
self.output_channels = num_output_channels
self.kernel_size = kernel_size
self.gru_encode_size = gru_size
self.conv3d = nn.ModuleList()
self.conv3d.append(nn.Sequential(
nn.Conv3d(self.input_channels, self.output_channels, self.kernel_size, stride=(1,2,2), padding =1),
nn.BatchNorm3d(self.output_channels),
nn.LeakyReLU(True)
))
channels = [self.output_channels]
for i in range(1, self.num_layers-1):
self.conv3d.append(nn.Sequential(
nn.Conv3d(channels[-1], channels[-1] * 2, self.kernel_size, stride=(1,2,2), padding=1),
nn.BatchNorm3d(channels[-1] * 2),
nn.LeakyReLU(True)
))
channels.append(2 * channels[-1])
self.conv3d.append(nn.Sequential(
nn.Conv3d(channels[-1], channels[-1], self.kernel_size, stride=(1,2,2), padding=(1,0,0)),
nn.BatchNorm3d(channels[-1]),
nn.LeakyReLU(True)))
self.gru_cell = nn.ModuleList()
for i in range(75):
self.gru_cell.append(nn.GRUCell(1024, self.gru_encode_size))
# self.gru = nn.GRU(1024, self.gru_encode_size, batch_first=True, bias=False)
self.linear = nn.Linear(self.gru_encode_size * 75, 1)
# self.sigmoid = nn.Sigmoid()
def forward(self, x):
x_batch_size = x.shape[0]
for con3d_layer in self.conv3d:
x = con3d_layer(x)
x = torch.squeeze(x).permute(2, 0, 1).contiguous()
assert len(self.gru_cell) == x.shape[0]
hx = torch.zeros(x_batch_size, self.gru_encode_size).to(torch.device('cuda' if torch.cuda.is_available() else 'cpu'))
output = []
for i in range(len(self.gru_cell)):
hx = self.gru_cell[i](x[i], hx)
output.append(torch.unsqueeze(hx, 1))
hx = torch.cat((output[0], output[1]), 1)
for i in range(2, len(self.gru_cell)):
hx = torch.cat((hx, output[i]), 1)
# self.gru.flatten_parameters()
# o, _ = self.gru(x)
o = hx.contiguous().view(x_batch_size, -1)
o = self.linear(o)
# o = self.sigmoid(o)
return o
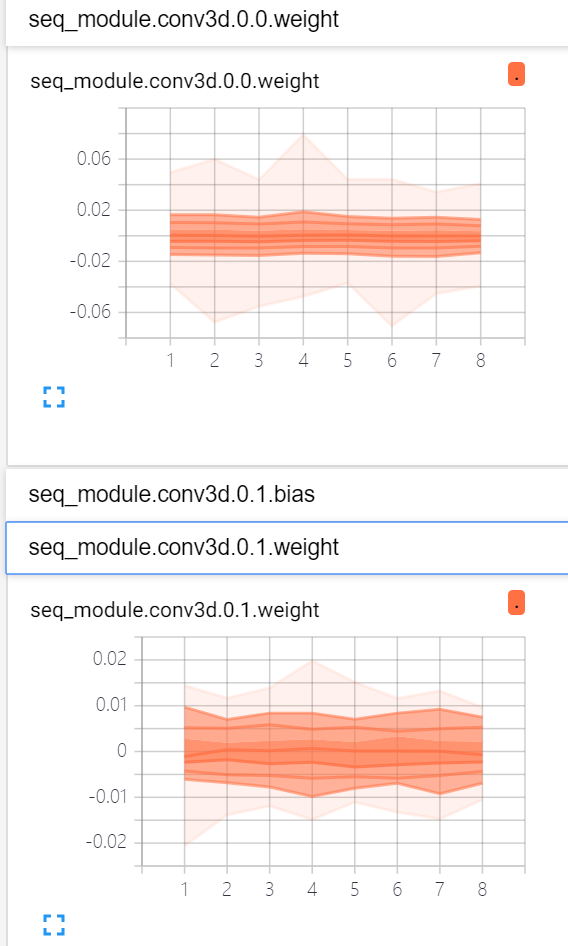
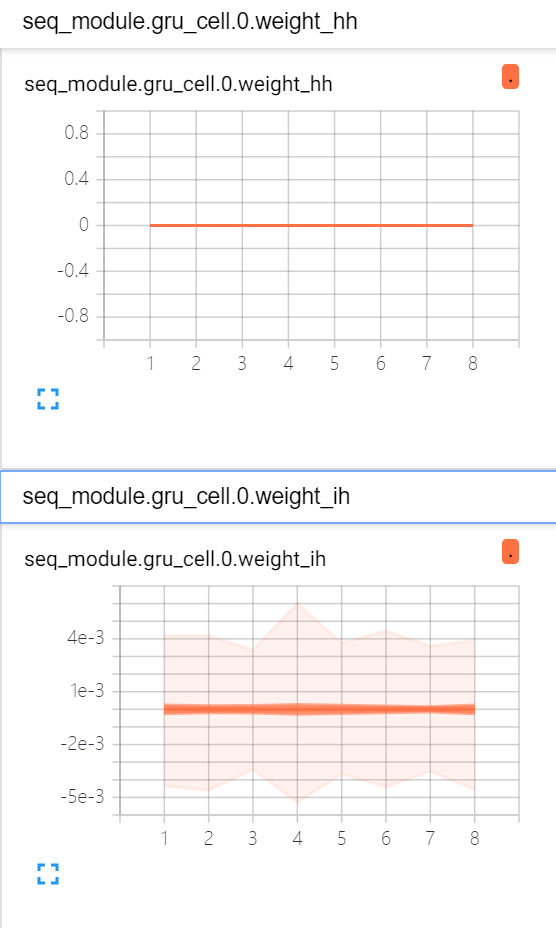
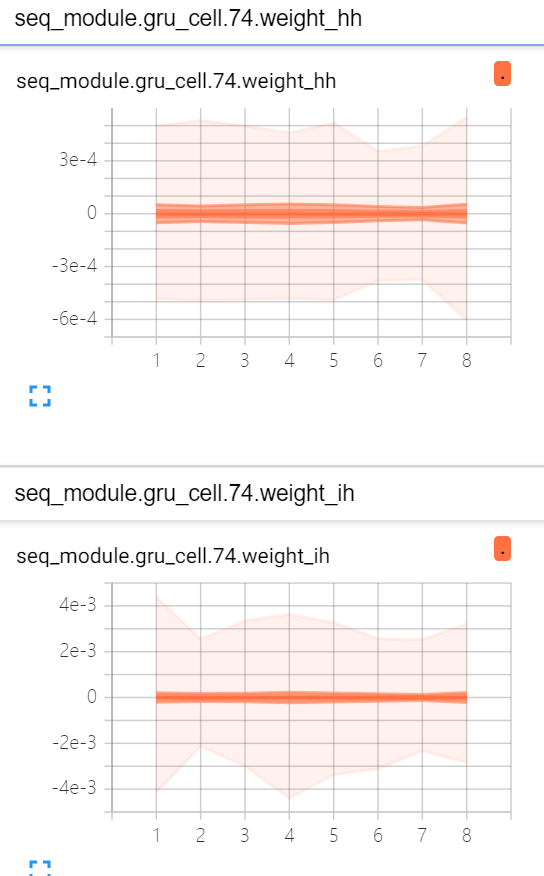
i’m reproducing a paper, this is part of the code. The gradient of each layer of the network is visualized, as shown in the figure above. When the gradients are transferred to the first GRUCell, the gradient decrease to 0. However, the gradient of convolution layer before the GRUCell is not zero. What causes the vanishing gradients? Is it related to learning rate?