I am training a Classification network
“arch” : “densenet161”,
“epochs” : 50,
“batch-size” : 24,
“learning-rate” : 0.0005,
“momentum” : 0.9,
“weight-decay” : 2e-5,
“image_size” : [112, 112]
If you use the usual method
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.Resize(args.image_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=None, pin_memory=True, sampler=None)
for i, (images, target) in enumerate(train_loader):
if torch.cuda.is_available():
if args.gpu is not None:
images = images.cuda(args.gpu, non_blocking=True)
target = target.cuda(args.gpu, non_blocking=True)
# compute output
output = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
the result will be normal.


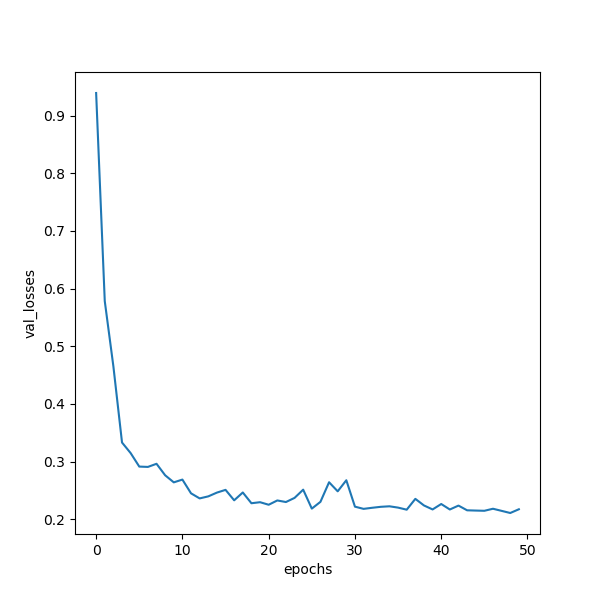
But actually the resolution of my dataset is different, So I want my input to be variable size
I’ve seen this and this
and change my program to
(1) gradient accumulation: batch-size = 1
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
def my_collate(batch):
data = [item[0] for item in batch]
target = [item[1] for item in batch]
target = torch.LongTensor(target)
return [data, target]
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, collate_fn=my_collate, shuffle=None, pin_memory=True, sampler=None)
if torch.cuda.is_available():
if args.gpu is not None:
images = images.cuda(args.gpu, non_blocking=True)
target = target.cuda(args.gpu, non_blocking=True)
# compute output
output = model(images)
if i < int(len(train_loader)/args.true_batch_size)*args.true_batch_size:
loss = criterion(output, target) / args.true_batch_size
else:
loss = criterion(output, target) / len(train_loader)%args.true_batch_size
loss.backward()
if ((i+1) % args.true_batch_size) == 0 or (i+1) == len(train_loader):
optimizer.step()
optimizer.zero_grad()
(2)Stack output: batch-size = 24
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
def my_collate(batch):
data = [item[0] for item in batch]
target = [item[1] for item in batch]
target = torch.LongTensor(target)
return [data, target]
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, collate_fn=my_collate, shuffle=None, pin_memory=True, sampler=None)
if torch.cuda.is_available():
#if args.gpu is not None:
# images = images.cuda(args.gpu, non_blocking=True)
target = target.cuda(args.gpu, non_blocking=True)
# compute output
for image in images: ##
output = model(image.unsqueeze(0).cuda(args.gpu, non_blocking=True))
if j == 0:
outputs = output.clone()
outputs = torch.cat((outputs,output), 0)
j += 1
output = outputs[1:]
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
But the results are terrible

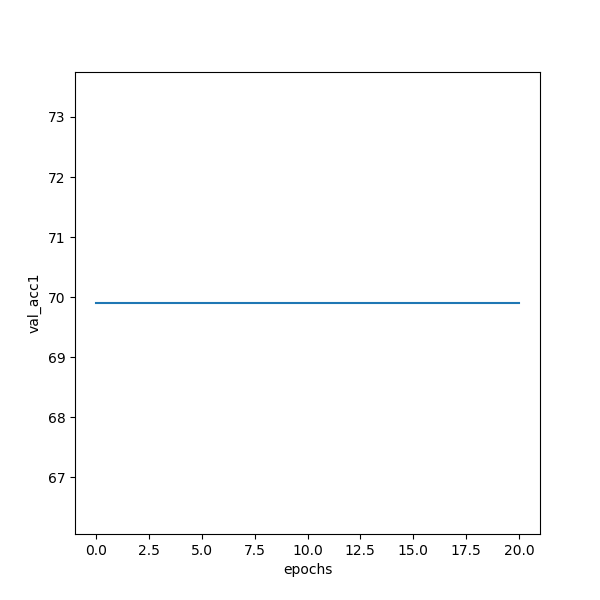
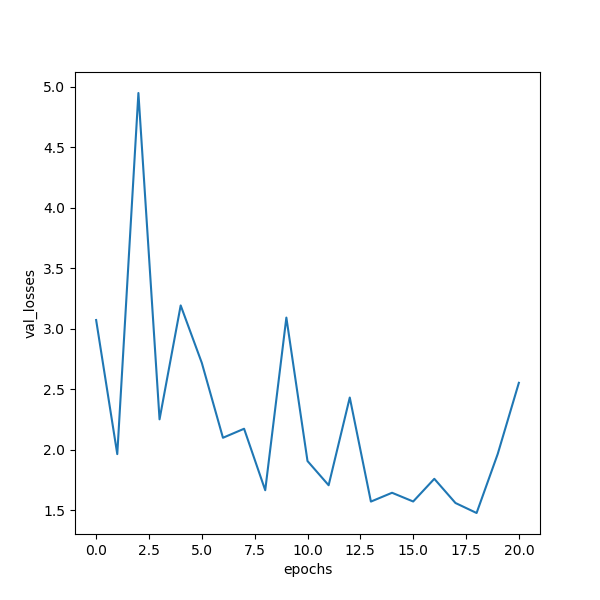
did i miss something?