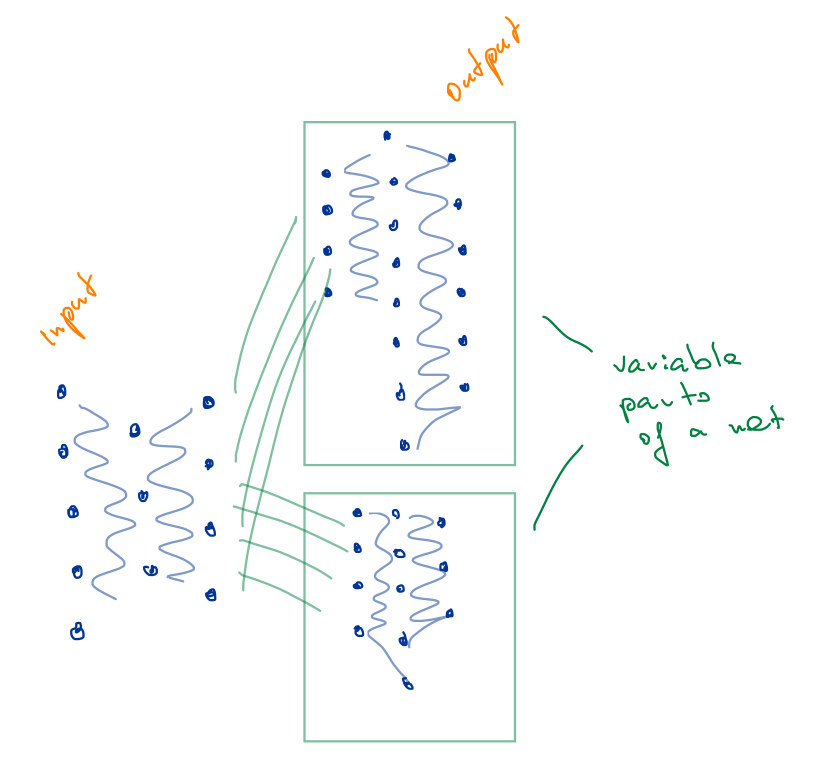
my question is about a variable output or some parts of a net which can vary. For example a flag would direct which output (or some part of a net) is to choose. That means that I have different hidden layers and with means of a flag it will be decided which is to take. Is there some examples available, could you provide someone.
You do a forward pass, after all the calculations, the final linear layer outputs a vector [1, nc], where nc is the number of classes.
This gets compared to the true classes, and we get a value of loss
This loss gets backpropagated.
Every parameter in the model gets updated with respect to this loss.
You have a better model! Hurray!
Let’s revise, the major the magic word backpropagation
This is an algorithm where each model parameter is compared to the loss.
And we calculate a gradient which is basically a number which has direction and magnitude
Now, this direction is indicated by torch.sign of this value, (i.e. whether positive or negative)
and moving the model parameter in this direction will increase the value of loss by a factor of magnitude.
So, we move in the opposite direction (i.e. negate the gradient) and thus decrease the loss
Since the computation graph will be created dynamically during the forward pass, only the parameters will be updated (and get a valid gradient) which were used to calculate the loss.
I.e. if you only use path1 during training, only self.path1 will be upgraded, while self.path2 keeps its initial values.