I am trying to learn the latent space representations of a high dimensional data with size (1288x1112) e.g. (samples x features).
For that I want to implement VAE with Beta weighted KLD.
I am using the following codes which are slightly different from traditional KLD equation format loss.
class Encoder(nn.Module):
def __init__(self, inputsize, latent_dims, mode):
super(Encoder, self).__init__()
self.mode = mode
self.layer_en1 = self.layer_(inputsize, 512, relu=True)
self.layer_en_xtra = self.layer_(512, 512, relu=True)
self.layer_en2 = self.layer_(512, latent_dims)
self.layer_en3 = self.layer_(512, latent_dims)
# self.dropout = nn.Dropout(0.5)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
init.kaiming_normal(module.weight)
if module.bias is not None:
module.bias.data.fill_(0)
elif isinstance(module, nn.BatchNorm1d):
module.weight.data.fill_(1)
if module.bias is not None:
module.bias.data.fill_(0)
def layer_(self, inputsize, outputsize, relu=True):
if relu:
layer = nn.Sequential(
nn.Linear(in_features=inputsize, out_features=outputsize),
nn.BatchNorm1d(num_features=outputsize),
nn.ReLU(inplace=False)
)
else:
layer = nn.Sequential(
nn.Linear(in_features=inputsize, out_features=outputsize),
nn.BatchNorm1d(num_features=outputsize)
)
return layer
def kl_divergence(self, z, mu, std):
p = torch.distributions.Normal(torch.zeros_like(mu), torch.ones_like(std))
q = torch.distributions.Normal(mu, std)
log_qzx = q.log_prob(z)
log_pz = p.log_prob(z)
# print("log_qzx", log_qzx, "log_pz", log_pz)
kl = (log_qzx - log_pz)
kl = kl.sum(-1)
# kl = torch.mean(-0.5 * torch.sum(1 + log_var - mu ** 2 - log_var.exp(), dim = 1), dim = 0)
# kl1 = (std ** 2 + mu ** 2 - torch.log(std) - 1 / 2).sum(-1)
# kl_t = torch.distributions.kl_divergence(q, p).sum(-1)
# print("kl_t shape", kl_t.shape)
return kl #, log_qzx.sum(-1), log_pz.sum(-1)#, kl1
def forward(self, x):#, mode='not_enc'):
x_ = self.layer_en1(x)
x_ = self.layer_en_xtra(x_)
mu = self.layer_en2(x_)
sigma = self.layer_en3(x_)
std = torch.exp(0.5 * sigma)
q = torch.distributions.Normal(mu, std)
z = q.rsample()
if self.mode == 'enc':
return z
else:
kl = self.kl_divergence(z, mu, std)
return z, kl
class Decoder(nn.Module):
def __init__(self, latent_dims, outputsize):
super(Decoder, self).__init__()
self.layer_de1 = self.layer_(latent_dims, 512, relu=True)
self.layer_de_xtra = self.layer_(512, 512, relu=True)
self.layer_de2 = self.layer_(512, outputsize, relu=False)
# self.dropout = nn.Dropout(0.5)
self.apply(self._init_weights)
# self.weight_init()
def weight_init(self):
for block in self._modules:
for m in self._modules[block]:
kaiming_init(m)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
init.kaiming_normal(module.weight)
if module.bias is not None:
module.bias.data.fill_(0)
elif isinstance(module, nn.BatchNorm1d):
module.weight.data.fill_(1)
if module.bias is not None:
module.bias.data.fill_(0)
def layer_(self, inputsize, outputsize, relu=True):
if relu:
layer = nn.Sequential(
nn.Linear(in_features=inputsize, out_features=outputsize),
nn.BatchNorm1d(num_features=outputsize),
nn.ReLU(inplace=False)
)
else:
layer = nn.Sequential(
nn.Linear(in_features=inputsize, out_features=outputsize),
nn.BatchNorm1d(num_features=outputsize)
)
return layer
def forward(self, z):
z_ = self.layer_de1(z)
z_ = self.layer_de_xtra(z_)
x_hat = torch.sigmoid(self.layer_de2(z_))
return x_hat
class VAE(nn.Module):
def __init__(self, inputsize, latent_dims, mode, beta=1.0):
super(VAE, self).__init__()
self.beta = beta
self.mode = mode
self.log_scale = nn.Parameter(torch.Tensor([0.0]))
self.encoder = Encoder(inputsize, latent_dims, self.mode)
self.decoder = Decoder(latent_dims, inputsize)
def gaussian_likelihood(self, x_hat, logscale, x):
scale = torch.exp(logscale)
# mean = x_hat
dist = torch.distributions.Normal(x_hat, scale)
log_pxz = dist.log_prob(x)
# print("prob of x from dist(x_hat, 1) >>", torch.exp(log_pxz).mean())
return log_pxz.sum(dim=1)
def forward(self, x):
z, kl = self.encoder(x) #, lq, lp
x_hat = self.decoder(z)
recon_loss = self.gaussian_likelihood(x_hat, self.log_scale, x)
elbo = -1 * ((self.beta * kl) + recon_loss)
elbo = elbo.mean()
return x_hat, elbo, kl.mean(), recon_loss.mean()
I have explored Beta value ranging from 1 to 20 but none are giving me a meaningful representation of the latent encoded space. I am using a Gaussian Mixture Model to cluster the latent space samples.
The loss curves (top - kld, middle-recon, bottom- total) with beta=1.5 looks like:
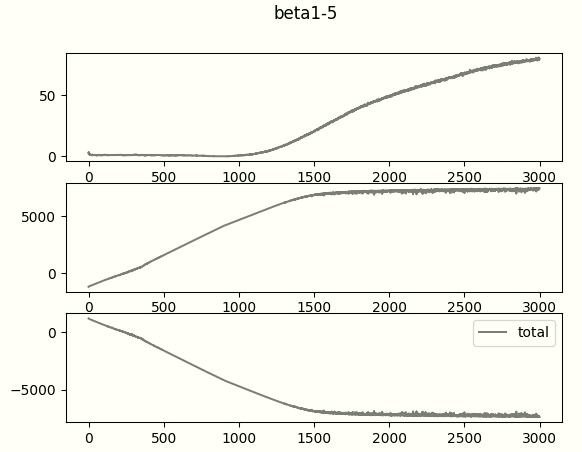
learning rate = 0.0005
Though the reconstruction decoder outputs are good with 99% match and lowers MSE, the encoded latent space (dimension = 5) aren’t good enough once clustered.
What shall I do?
Concerns:
-
The reconstruction loss is summed over 1112 inputs whereas KLD is summed over 5. Does it overweight the reconstruction loss compared to the KLD?
-
Anything about weight init? Kaiming vs Xavier?