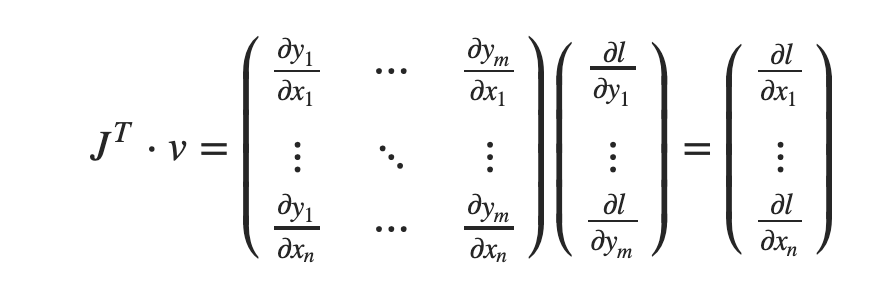In the autograd tutorial in the 60 minute blitz, the vector jacobian product calculation seems to miss a constant factor (m) on the right hand side (for example, in the first product, there are m equal terms of dl/dx1, that add to m.dl/dx1 - not just dl.dx1:
Not it wouldn’t be m*, it is that: dl/dx1 = sum_i (dl/dyi * dyi/dx1). As you need to accumulate the gradient contribution from all the outputs to get the full gradient.
I don’t understand - sum_i (dl/dyi * dyi/dx1) = sum_i (dl/dx1) - but the sum is over m terms, and all terms are dl/dx1 - so, why isn’t that m times dl/dx1?
We are trying to compute the matrix-vector product - and I am claiming that the first term computes to m.dl/dx1, and not dl/dx1 as shown. Just look at the Jacobian transposed as shown, and multiplying terms of first row of jacobian transposed and v, and add them up. The canceling of dy_i is exactly permitted by the chain rule, because, for each respective product term, it is dy1, dy2, etc. respectively, in both the numerator and denominator. So, for the first term of the output vector, the sum is (dy1/dx1 * dl/dy1) + (dy2/dx1 * dl/dy2) + ... , and in each term, the dyi term cancels out, by the chain rule.
I totally might be missing something, but I don’t see it.
All we’re doing here is doing an abuse of notation. You should say that dl/dyi * dyi/dx = dl/dx_i where the _i signifies that this only considers the contribution from y_i.
If we write things down: You have a function Y = f(X).
And we are given for every entry in Y, a gradient wrt a loss dl/dyi.
Now if you want to compute the gradient for a given entry in X, let’s say x0, you want dl/dx0. And to compute this, you use the chain rule to consider all the elements in Y that contribute to l which were made from x0. And so dl/dx0 = sum_i (dl/dyi * dyi/dx0) where i allows you to consider all the outputs one by one.
Ok, got it. Thanks a lot for explaining. My partial diffferential calculus is very rusty, and I was confusing between partial derivative chain rule (where it does not make sense to cancel out the dx terms in each partial derivative product, since they are different partial derivative terms being multiplied) with the univariate chain rule, where we can cancel out such terms.
For others who land here with similar confusion, This article about chain rule for partial derivative (see case 2) also helped clarify.
Thanks again for clarifying - this was very baffling - now it is clear.
Anand