Hi Jean Paul!
Here’s the best I could come up with for a loop-free version:
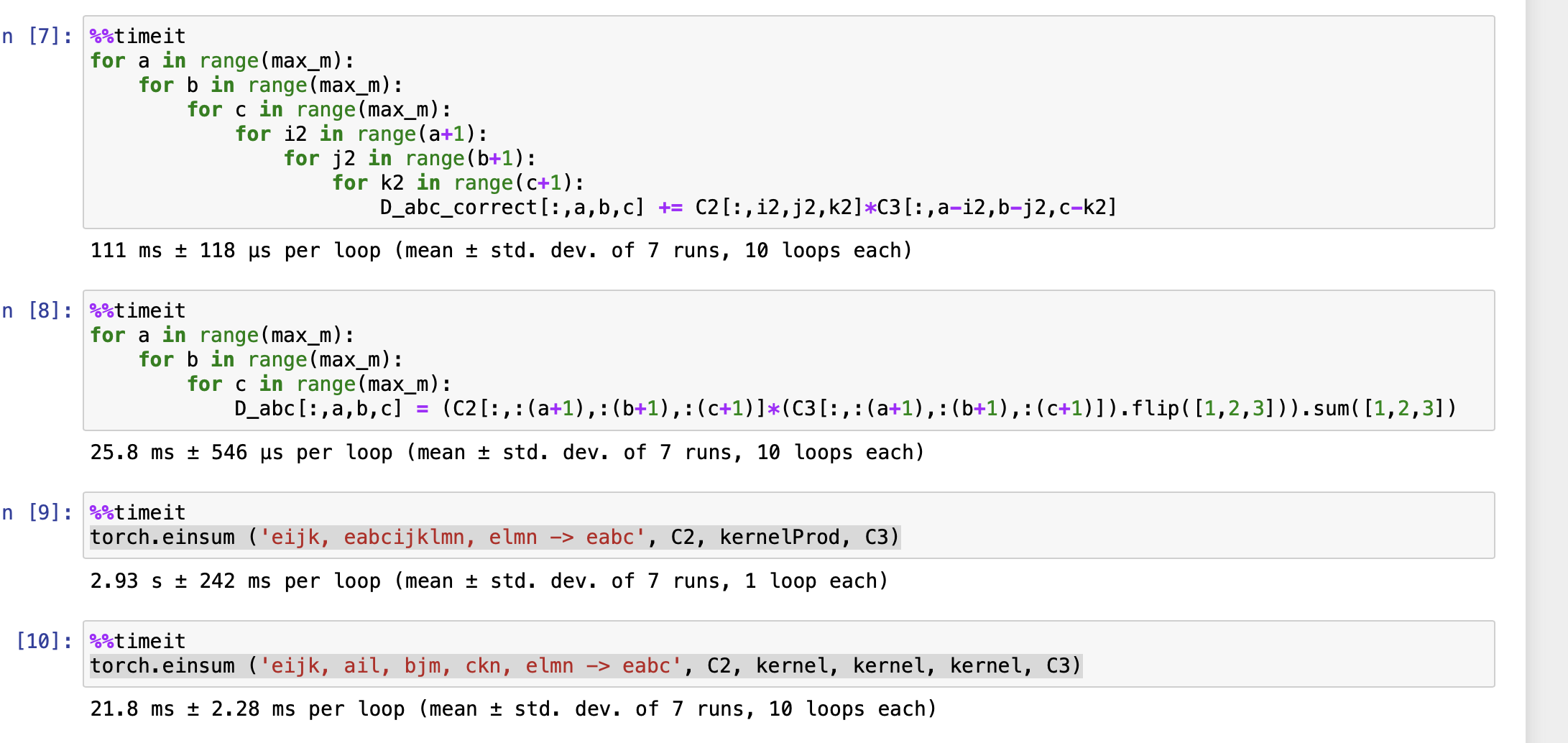
At the cost of materializing a large, nine-dimensional “contraction-kernel”
tensor, you can replace the six for-loops with a single einsum() call.
Here is a script that implements this:
import torch
print (torch.__version__)
_ = torch.manual_seed (2023)
num_faces = 10
max_m = 5
C2 = torch.rand(num_faces,max_m,max_m,max_m)
C3 = torch.rand(num_faces,max_m,max_m,max_m)
# This is the naive slow implementation with 6 loops, but is correct
D_abc_correct = torch.zeros(num_faces,max_m,max_m,max_m)
for a in range(max_m):
for b in range(max_m):
for c in range(max_m):
for i2 in range(a+1):
for j2 in range(b+1):
for k2 in range(c+1):
D_abc_correct[:,a,b,c] += C2[:,i2,j2,k2]*C3[:,a-i2,b-j2,c-k2]
# set up "contraction kernel"
inds = torch.arange (max_m)
kernel = ((inds.unsqueeze (0) + inds.unsqueeze (1)).unsqueeze (0) == inds.unsqueeze (-1).unsqueeze (-1)).float()
print ('check one slice of kernel:')
print (kernel[2]) # check one slice to see what it looks like
kernelProd = torch.einsum ('ail, bjm, ckn -> abcijklmn', kernel, kernel, kernel) # "outer-product" kernel
print ('kernelProd is big, but rather sparse:')
print ('numel(): ', kernelProd.numel()) # quite big
print ('num-zero: ', (kernelProd == 0.0).sum().item()) # with lots of zeros
print ('frac-nonzero:', (kernelProd != 0.0).sum().item() / kernelProd.numel()) # so rather sparse
kernelProd = kernelProd.unsqueeze (0).expand (num_faces, -1, -1, -1, -1, -1, -1, -1, -1, -1) # expand() view with num_faces dimension
D_abc_B = torch.einsum ('eijk, eabcijklmn, elmn -> eabc', C2, kernelProd, C3)
# check einsum result
print ('torch.allclose (D_abc_correct, D_abc_B):', torch.allclose (D_abc_correct, D_abc_B))
And here is its output:
2.0.0
check one slice of kernel:
tensor([[0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
kernelProd is big, but rather sparse:
numel(): 1953125
num-zero: 1949750
frac-nonzero: 0.001728
torch.allclose (D_abc_correct, D_abc_B): True
Note, you can reuse kernelProd, so even if you have to run this
computation multiple times for differing values of the input tensors,
C2 and C3, you only have to construct kernelProd once.
Best.
K. Frank