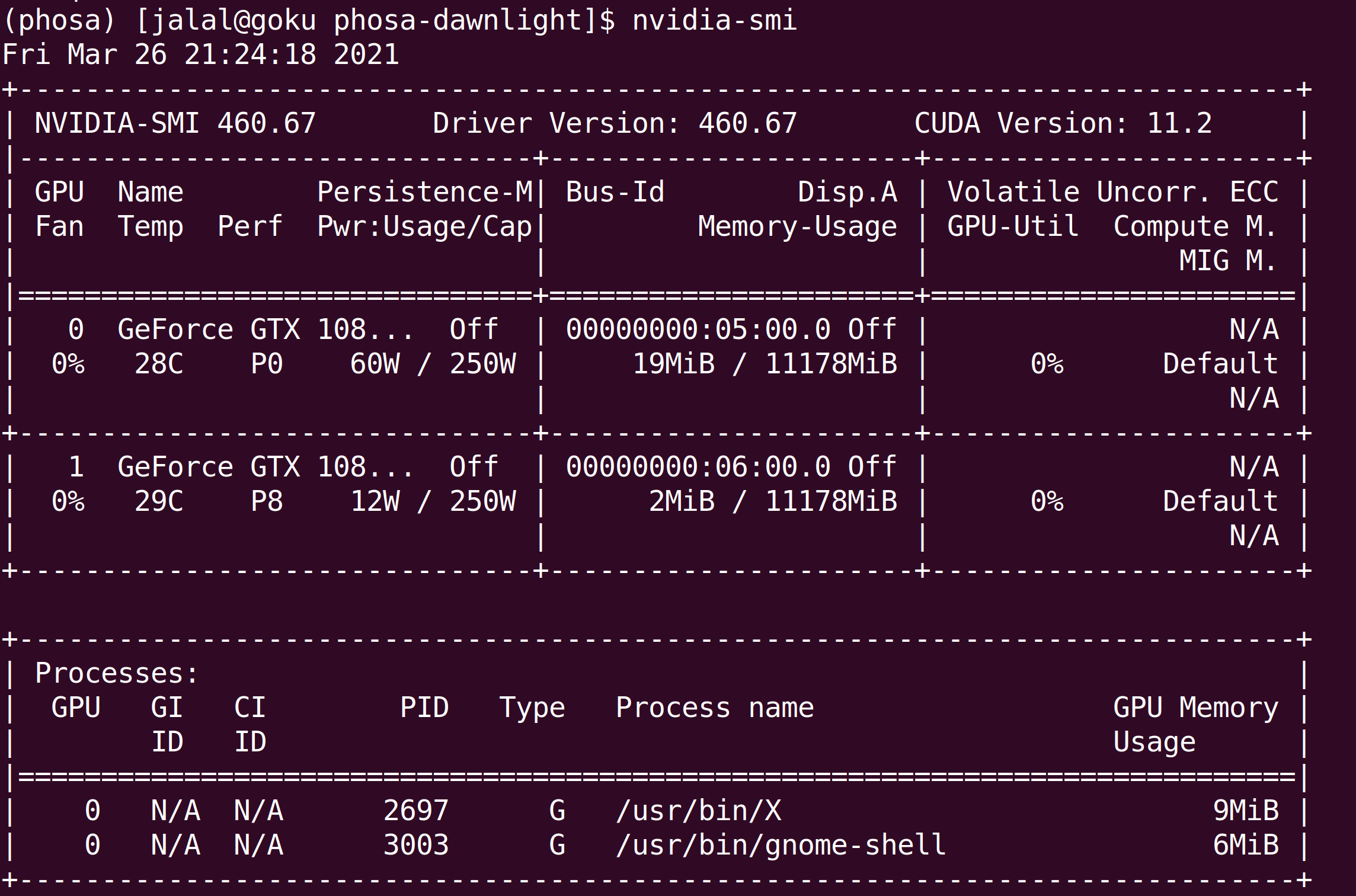
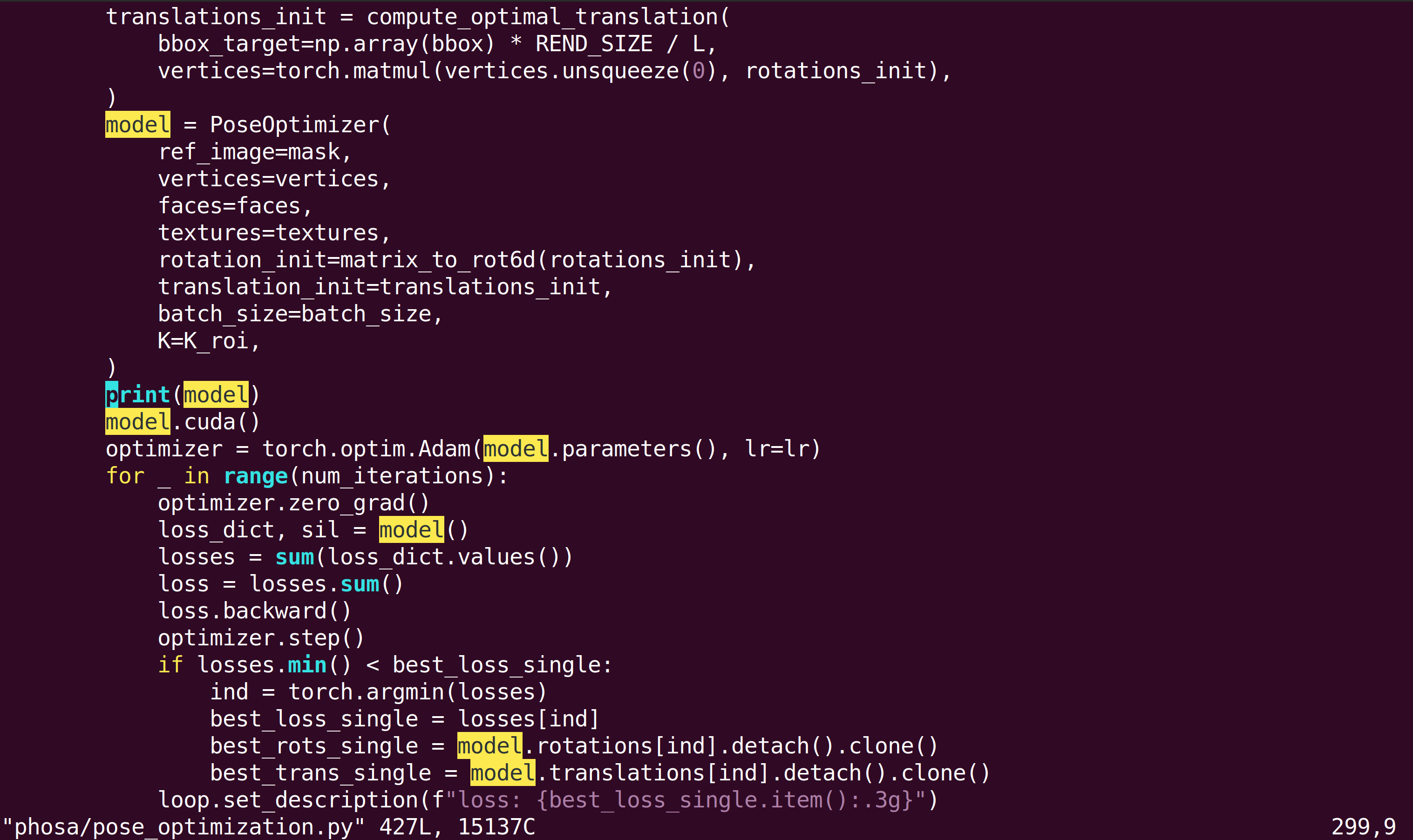
How can I fix this?
(phosa) [jalal@goku phosa]$ python demo.py --filename input/dark_bat.jpg --class_name bat
2021-03-26 16:55:48,497 INFO Calling with args: Namespace(class_name='bat', filename='input/dark_bat.jpg', lw_collision=None, lw_depth=None, lw_inter=None, lw_inter_part=None, lw_scale=None, lw_scale_person=None, lw_sil=None, mesh_index=0, output_dir='output')
2021-03-26 16:55:51,993 INFO Loading checkpoint from detectron2://PointRend/InstanceSegmentation/pointrend_rcnn_R_50_FPN_3x_coco/164955410/model_final_3c3198.pkl
2021-03-26 16:55:51,995 INFO URL https://dl.fbaipublicfiles.com/detectron2/PointRend/InstanceSegmentation/pointrend_rcnn_R_50_FPN_3x_coco/164955410/model_final_3c3198.pkl cached in /home/grad3/jalal/.torch/fvcore_cache/detectron2/PointRend/InstanceSegmentation/pointrend_rcnn_R_50_FPN_3x_coco/164955410/model_final_3c3198.pkl
2021-03-26 16:55:52,104 INFO Reading a file from 'Detectron2 Model Zoo'
WARNING: You are using a SMPL model, with only 10 shape coefficients.
Downloading: "https://download.pytorch.org/models/resnet50-19c8e357.pth" to /home/grad3/jalal/.cache/torch/hub/checkpoints/resnet50-19c8e357.pth
100%|██████████████████████████████████████████████████████████████████████████████████████████| 97.8M/97.8M [00:00<00:00, 108MB/s]
class_name: bat
0%| | 0/12500.0 [00:00<?, ?it/s]Traceback (most recent call last):
File "demo.py", line 145, in <module>
main(get_args())
File "demo.py", line 121, in main
instances=instances, class_name=args.class_name, mesh_index=args.mesh_index
File "/scratch3/research/code/phosa/phosa/pose_optimization.py", line 406, in find_optimal_poses
num_initializations=num_initializations,
File "/scratch3/research/code/phosa/phosa/pose_optimization.py", line 287, in find_optimal_pose
vertices=torch.matmul(vertices.unsqueeze(0), rotations_init),
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemmStridedBatched( handle, opa, opb, m, n, k, &alpha, a, lda, stridea, b, ldb, strideb, &beta, c, ldc, stridec, num_batches)`
0%| | 0/12500.0 [00:00<?, ?it/s]
(phosa) [jalal@goku ~]$ python
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'1.8.1+cu111'
>>> torch.cuda.is_available()
True
and
$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.9.2009 (Core)
Release: 7.9.2009
Codename: Core
and
(phosa) [jalal@goku ~]$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
and
(phosa) [jalal@goku ~]$ python collect_env.py
Collecting environment information...
PyTorch version: 1.8.1+cu111
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: CentOS Linux release 7.9.2009 (Core) (x86_64)
GCC version: (GCC) 7.3.0
Clang version: 3.4.2 (tags/RELEASE_34/dot2-final)
CMake version: version 3.10.0-rc5
Python version: 3.6 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: 10.0.130
GPU models and configuration:
GPU 0: GeForce GTX 1080 Ti
GPU 1: GeForce GTX 1080 Ti
Nvidia driver version: 450.51.06
cuDNN version: Probably one of the following:
/scratch/system/usr/local/cuda-10.0/targets/x86_64-linux/lib/libcudnn.so.7.4.2
/scratch/system/usr/local/cuda-9.0/targets/x86_64-linux/lib/libcudnn.so.7.0.5
/scratch/system/usr/local/cuda-9.2/targets/x86_64-linux/lib/libcudnn.so.7.6.5
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.7.6.5
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.8.0.2
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.2
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.2
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.2
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.2
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.2
/scratch2/system/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.2
/scratch2/system/usr/local/cuda-8.0/targets/x86_64-linux/lib/libcudnn.so.5.1.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] neural-renderer-pytorch==1.1.3
[pip3] numpy==1.19.5
[pip3] torch==1.8.1+cu111
[pip3] torchaudio==0.8.1
[pip3] torchgeometry==0.1.2
[pip3] torchvision==0.9.1+cu111
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.0.130 0
[conda] mkl 2018.0.3 1
[conda] mkl-service 1.1.2 py36h17a0993_4
[conda] mkl_fft 1.0.10 py36_0 conda-forge
[conda] mkl_random 1.0.2 py36_0 conda-forge
[conda] msgpack-numpy 0.4.4.3 pypi_0 pypi
[conda] numpy 1.19.4 pypi_0 pypi
[conda] numpydoc 0.9.1 py_0 conda-forge
[conda] pytorch 1.1.0 py3.6_cuda10.0.130_cudnn7.5.1_0 pytorch
[conda] pytorch-nightly 1.0.0.dev20190328 py3.6_cuda10.0.130_cudnn7.4.2_0 pytorch
[conda] pytorchviz 0.0.1 pypi_0 pypi
[conda] torchvision 0.3.0 py36_cu10.0.130_1 pytorch
Please let me know if more details is required.