Hi Everybody,
I am seeing a very consistent memory leak when training a model with pytorch. Every epoch I am loosing 108k+/- 6k pages of cpu memory. I tried with numworker = 0 and 4 and with and without GPU in all cases I am loosing about the same amount of memory each cycle. Finally after about 160 epoch’s my training will killed by the queuing system for exceeding the requested memory (if nworker=0) or crash with an error message like below or a different memory error (nworker>0):
File “/gstore/apps/Anaconda3/5.0.1/lib/python3.6/multiprocessing/process.py”, line 105, in start
self._popen = self._Popen(self)
File “/gstore/apps/Anaconda3/5.0.1/lib/python3.6/multiprocessing/context.py”, line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File “/gstore/apps/Anaconda3/5.0.1/lib/python3.6/multiprocessing/context.py”, line 277, in _Popen
return Popen(process_obj)
File “/gstore/apps/Anaconda3/5.0.1/lib/python3.6/multiprocessing/popen_fork.py”, line 20, in init
self._launch(process_obj)
File “/gstore/apps/Anaconda3/5.0.1/lib/python3.6/multiprocessing/popen_fork.py”, line 67, in _launch
self.pid = os.fork()
OSError: [Errno 12] Cannot allocate memory
I have counted the number and type of python objects in each epoch following this suggestion:
https://tech.labs.oliverwyman.com/blog/2008/11/14/tracing-python-memory-leaks/
and found that after about 5 epochs the number of python object does not change at all. So my conclusion is that the leak might be in the torch C code.
Any ideas how I could further debug this?
Thanks,
Alberto
Some more information in case this helps:
- My training involves a variable number of records per minibatch
- My training set size is 114989 “objects” in minibatches of 1500
- The network is simple but some what unconventional: each “object” will result in multiple (varying 0-20) records passed through multiple fully connected layers. The results are then “averaged” before computing the final score and the loss function
- I tried adding torch.backend.cudnn.enalbled = False with no effect.
- I am using pytorch 0.4.0 on linux
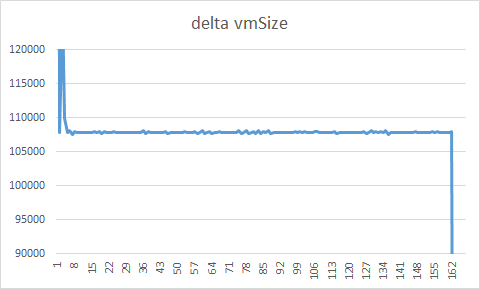
vmSize change from one epoch to next (note the last dip is due to the system crashing):