Hello guys! I’m having a bit of a problem trying to implement a small LSTM network.
I’m using a sequence of 20 values as input and the network has to predict certain output. The data is scaled between 0 and 1, and the dataset looks like this:
Input:
array([[0.3616897 , 0.50186179, 0.46220047, 0.48337192],
[0.38939199, 0.5308964 , 0.47071214, 0.48807264],
[0.43114892, 0.55613415, 0.47903991, 0.49106299],
...,
[0.48847856, 0.55368452, 0.48759646, 0.48916795],
[0.49450675, 0.57330196, 0.48922357, 0.49509893],
[0.49728463, 0.58997826, 0.49048734, 0.50129733]])
Output:
array([[0.33857308, 0.50931249],
[0.3834156 , 0.53883397],
[0.42320043, 0.5688971 ],
...,
[0.48872479, 0.56165727],
[0.50050588, 0.58804321],
[0.49346006, 0.59605735]])
So I would use the 20 first values of Input as the first sequence and the desired output would be the 20th element of Output.
This is how my network class looks like:
class neuralNet(nn.Module):
def __init__(self):
super(neuralNet, self).__init__()
self.lstm = nn.LSTM(4, 4)
self.fc1 = nn.Linear(4, 16)
self.out_real = nn.Linear(16, 1)
self.out_im = nn.Linear(16, 1)
def forward(self, X):
x, _ = self.lstm(X)
x = F.leaky_relu(self.fc1(x[-1].view(X.shape[1], -1)))
sal_real = F.leay_relu(self.out_real(x))
sal_im = F.leaky_relu(self.out_im(x))
return sal_real, sal_im
This is how I define the Dataloader:
class _data_(Dataset):
def __init__(self, X, y, window):
self.X = X
self.y = y
self.window = window
def __len__(self):
return self.X.shape[0]
def __getitem__(self, idx):
return self.X[idx:idx+(self.window)], self.y[idx+self.window-1]
I use the Adam optimizer, a batch size of 1024, however I’ve tried with several different batch sizes and learning rates, and this is how my training loop looks like:
network.train()
train_loss = []
for epochs in range(100):
for x, y_true in loader:
optimizer.zero_grad()
out_real, out_im = network(x.view(20, 1024, 4).type(torch.FloatTensor))
loss_1 = torch.sqrt(((out_real-y_true[:, 0].view(-1, 1).type(torch.FloatTensor))**2).mean())
loss_2 = torch.sqrt(((out_im-y_true[:, 1].view(-1, 1).type(torch.FloatTensor))**2).mean())
loss = loss_1+loss_2
loss.backward()
optimizer.step()
train_loss.append(loss.detach().numpy().reshape(-1))
print(epochs)
However, the loss quickly drops to around 0.23 and then just stays there, predicting very similar values no matter the input. I checked the gradients of the LSTM layer and the gradients are very small:
print(network.lstm.weight_ih_l0.grad)
tensor([[ 2.4166e-05, 1.1411e-04, 6.1285e-05, 8.6557e-05],
[ 5.0125e-05, -1.9328e-05, 1.7648e-05, 2.4593e-06],
[ 6.6281e-05, 6.8287e-05, 6.3350e-05, 6.7243e-05],
[ 2.7249e-05, 5.8169e-05, 4.2136e-05, 5.0256e-05],
[ 2.1470e-05, 1.0980e-04, 5.8128e-05, 8.3109e-05],
[ 7.5999e-05, -7.7817e-06, 3.6380e-05, 1.7472e-05],
[ 1.1556e-04, 1.3376e-04, 1.1724e-04, 1.2893e-04],
[ 3.5581e-05, 6.9475e-05, 4.9838e-05, 5.9006e-05],
[-1.0905e-04, -4.3272e-04, -2.4602e-04, -3.3566e-04],
[ 4.4844e-04, 2.4696e-06, 2.3953e-04, 1.3694e-04],
[ 1.7014e-04, 1.8785e-04, 1.6552e-04, 1.8307e-04],
[-2.9961e-04, -1.2150e-03, -6.4513e-04, -9.0194e-04],
[ 2.6096e-05, 2.2836e-04, 1.0026e-04, 1.6018e-04],
[ 1.4060e-04, -6.1505e-05, 3.9611e-05, -1.6231e-05],
[ 2.9458e-04, 1.2405e-04, 1.8125e-04, 1.3770e-04],
[ 4.3766e-05, 1.5784e-04, 8.4850e-05, 1.1989e-04]])
The loss function:
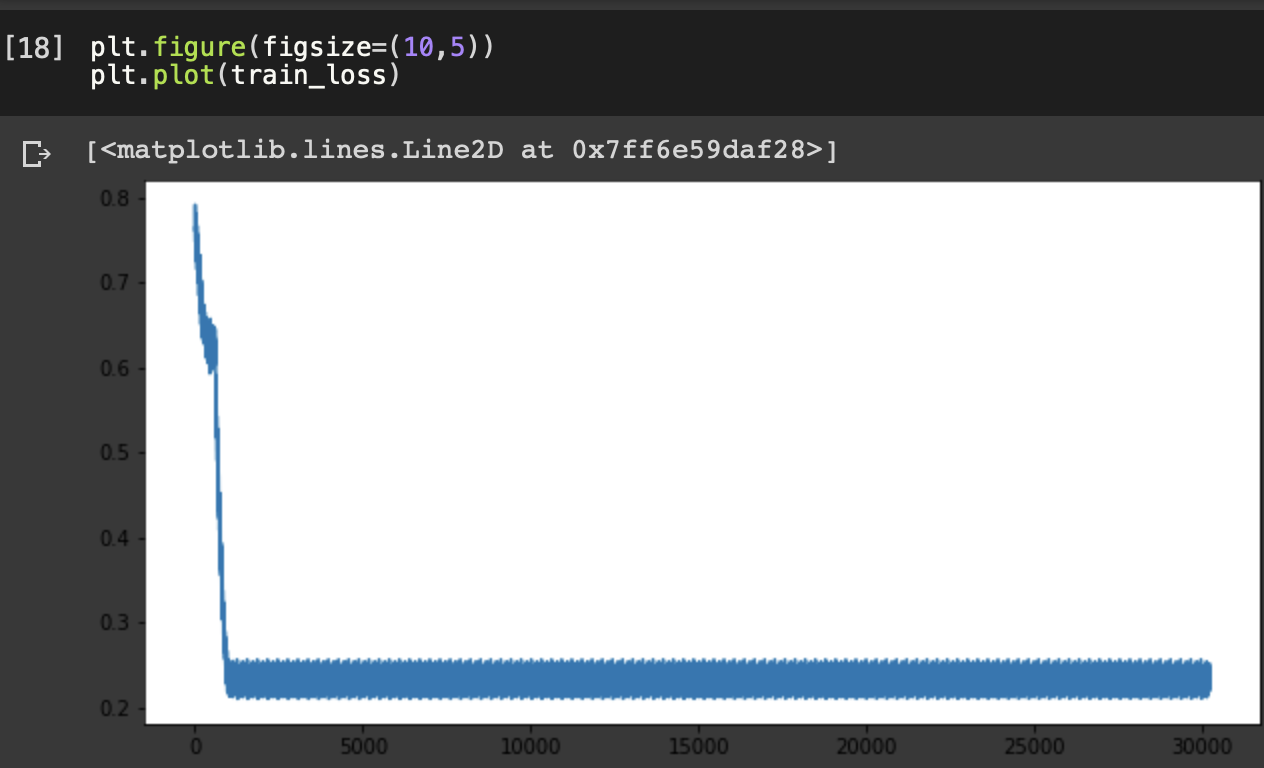
This is my first time working with LSTMs, and I’ve tried with different widths/depths and different activation functions on the neural network, but I’m still stuck with the same problem, so I’m assuming the problem is with my code.
Thanks a lot in advance!